This Hands-On Lab exercise is designed to help you learn how to build and manage Snowflake Cortex LLM nodes within Coalesce. In this Snowflake award winning exercise, you'll explore the Coalesce interface, learn how to easily transform and model your data with our core capabilities, and use the Cortex LLM functions node that Coalesce provides users.
What you'll need
- A Snowflake trial account
- A Coalesce trial account created via Snowflake Partner Connect
- Basic knowledge of SQL, database concepts, and objects
- The Google Chrome browser
What you'll build
- A Directed Acyclic Graph (DAG) that builds an Cortex LLM Pipeline
What you'll learn
- How to navigate the Coalesce interface
- Configure storage locations and mappings
- How to add data sources to your graph
- How to prepare your data for transformations with Stage nodes
- How to union tables
- How to set up and configure Cortex LLM Nodes
- How to analyze the output of your results in Snowflake
By completing the steps we've outlined in this guide, you'll have mastered the basics of Coalesce and can venture into our more advanced features.
Coalesce is the first cloud-native, visual data transformation platform built for Snowflake. Coalesce enables data teams to develop and manage data pipelines in a sustainable way at enterprise scale and collaboratively transform data without the traditional headaches of manual, code-only approaches.
What can I do with Coalesce?
With Coalesce, you can:
- Develop data pipelines and transform data as efficiently as possible by coding as you like and automating the rest, with the help of an easy-to-learn visual interface
- Work more productively with customizable templates for frequently-used transformations, auto-generated and standardized SQL, and full support for Snowflake functionality
- Analyze the impact of changes to pipelines with built-in data lineage down to the column level
- Build the foundation for predictable DataOps through automated CI/CD workflows and full git integration
- Ensure consistent data standards and governance across pipelines, with data never leaving your Snowflake instance
How is Coalesce different?
Coalesce's unique architecture is built on the concept of column-aware metadata, meaning that the platform collects, manages, and uses column- and table-level information to help users design and deploy data warehouses more effectively. This architectural difference gives data teams the best that legacy ETL and code-first solutions have to offer in terms of flexibility, scalability and efficiency.
Data teams can define data warehouses with column-level understanding, standardize transformations with data patterns (templates) and model data at the column level.
Coalesce also uses column metadata to track past, current, and desired deployment states of data warehouses over time. This provides unparalleled visibility and control of change management workflows, allowing data teams to build and review plans before deploying changes to data warehouses.
Core Concepts in Coalesce
Snowflake
Coalesce currently only supports Snowflake as its target database, As you will be using a trial Coalesce account created via Partner Connect, your basic database settings will be configured automatically and you can instantly build code.
Organization
A Coalesce organization is a single instance of the UI, set up specifically for a single prospect or customer. It is set up by a Coalesce administrator and is accessed via a username and password. By default, an organization will contain a single Project and a single user with administrative rights to create further users.
Projects
Projects provide a way of completely segregating elements of a build, including the source and target locations of data, the individual pipelines and ultimately the git repository where the code is committed. Therefore teams of users can work completely independently from other teams who are working in a different Coalesce Project.
Each Project requires access to a git repository and Snowflake account to be fully functional. A Project will default to containing a single Workspace, but will ultimately contain several when code is branched.
Workspaces vs Environments
A Coalesce Workspace is an area where data pipelines are developed that point to a single git branch and a development set of Snowflake schemas. One or more users can access a single Workspace. Typically there are several Workspaces within a Project, each with a specific purpose (such as building different features). Workspaces can be duplicated (branched) or merged together.
A Coalesce Environment is a target area where code and job definitions are deployed to. Examples of an environment would include QA, PreProd and Production.
It isn't possible to directly develop code in an Environment, only deploy to there from a particular Workspace (branch). Job definitions in environments can only be run via the CLI or API (not the UI). Environments are shared across an entire project, therefore the definitions are accessible from all workspaces. Environments should always point to different target schemas (and ideally different databases), than any Workspaces.
You will be stepping into the shoes of the lead Data & Analytics manager for the fictional Snowflake Ski Store brand. You are responsible for building and managing data pipelines that deliver insights to the rest of the company in a timely and actionable manner. Management has asked that they receive insight into how customers feel about product defects, and which customers are the most unhappy when defects are received. The data you will be analyzing is from the Snowflake Ski Store call center, where customers call in with questions or complaints. Each conversation is recorded and stored as a call transcript within a table of your database. This is what you will use to uncover the insights that management is seeking.
Management is hoping you can build and operationalize a pipeline that uses Large Language Model functions that allow them to have consistent insight into customer sentiment and around the brand and product.
To complete this lab, please create free trial accounts with Snowflake and Coalesce by following the steps below. You have the option of setting up Git-based version control for your lab, but this is not required to perform the following exercises. Please note that none of your work will be committed to a repository unless you set Git up before developing.
We recommend using Google Chrome as your browser for the best experience.
Step 1: Create a Snowflake Trial Account
- Fill out the Snowflake trial account form here. Use an email address that is not associated with an existing Snowflake account.
- When signing up for your Snowflake account, select the region that is physically closest to you and choose Enterprise as your Snowflake edition. Please note that the Snowflake edition, cloud provider, and region used when following this guide do not matter.
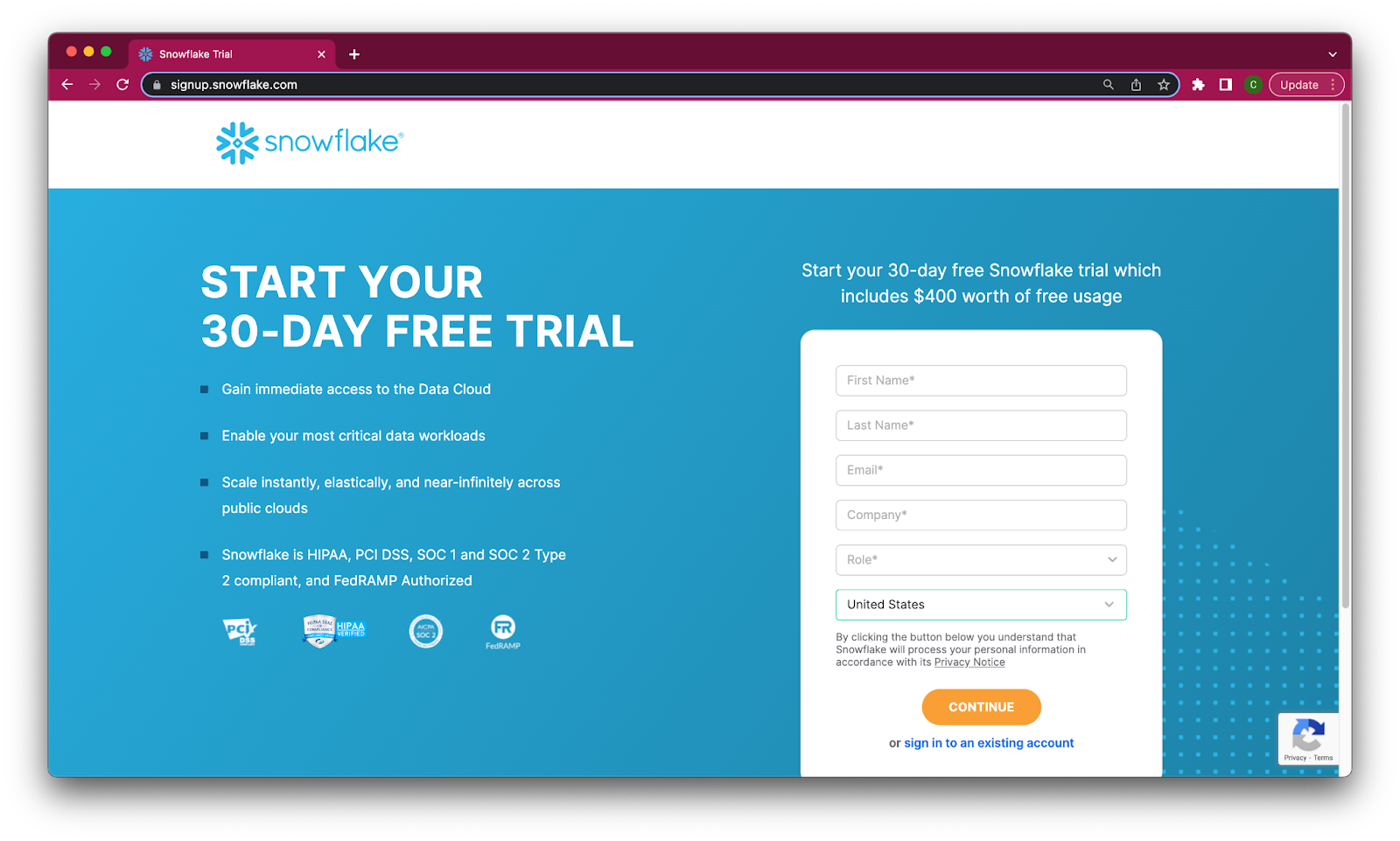
- After registering, you will receive an email from Snowflake with an activation link and URL for accessing your trial account. Finish setting up your account following the instructions in the email.
Step 2: Create a Coalesce Trial Account with Snowflake Partner Connect
Once you are logged into your Snowflake account, sign up for a free Coalesce trial account using Snowflake Partner Connect. Check your Snowflake account profile to make sure that it contains your fist and last name.
Once you are logged into your Snowflake account, sign up for a free Coalesce trial account using Snowflake Partner Connect. Check your Snowflake account profile to make sure that it contains your fist and last name.
- Select Data Products > Partner Connect in the navigation bar on the left hand side of your screen and search for Coalesce in the search bar.
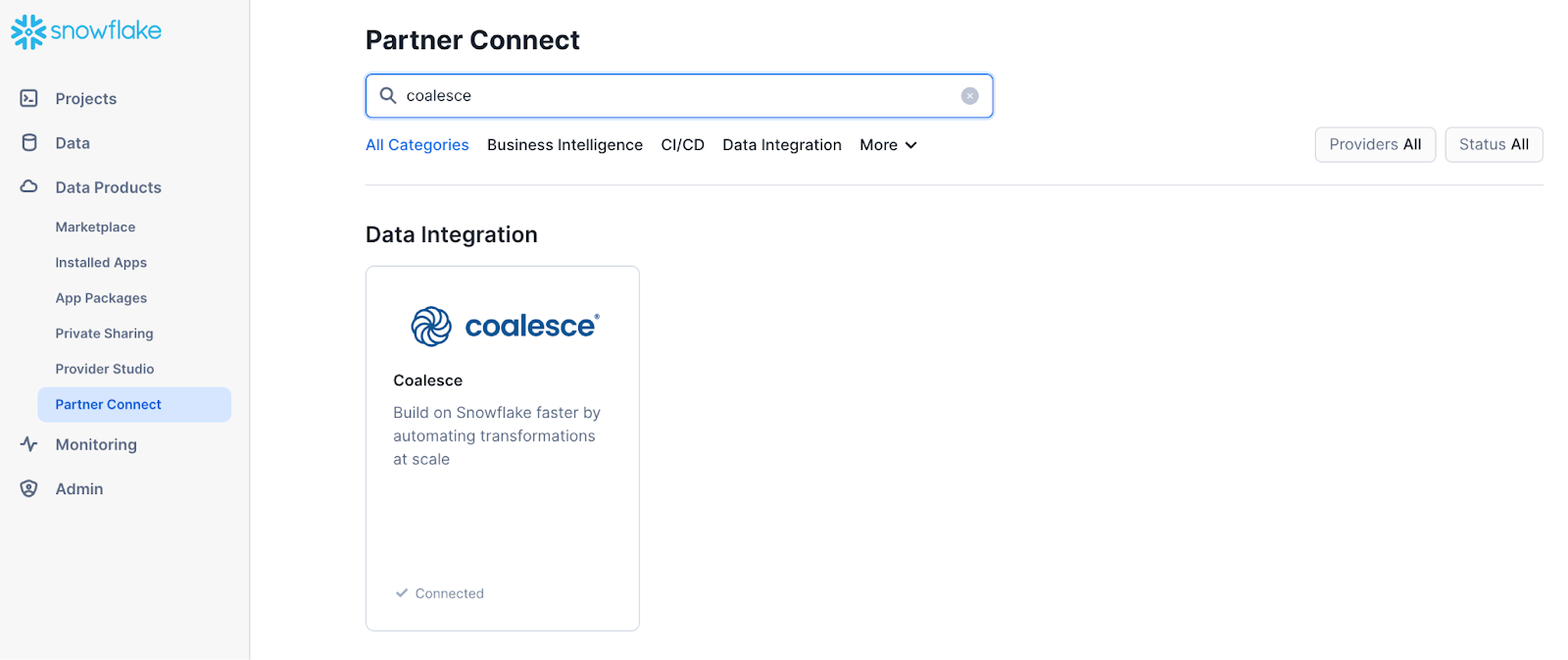
- Review the connection information and then click Connect.
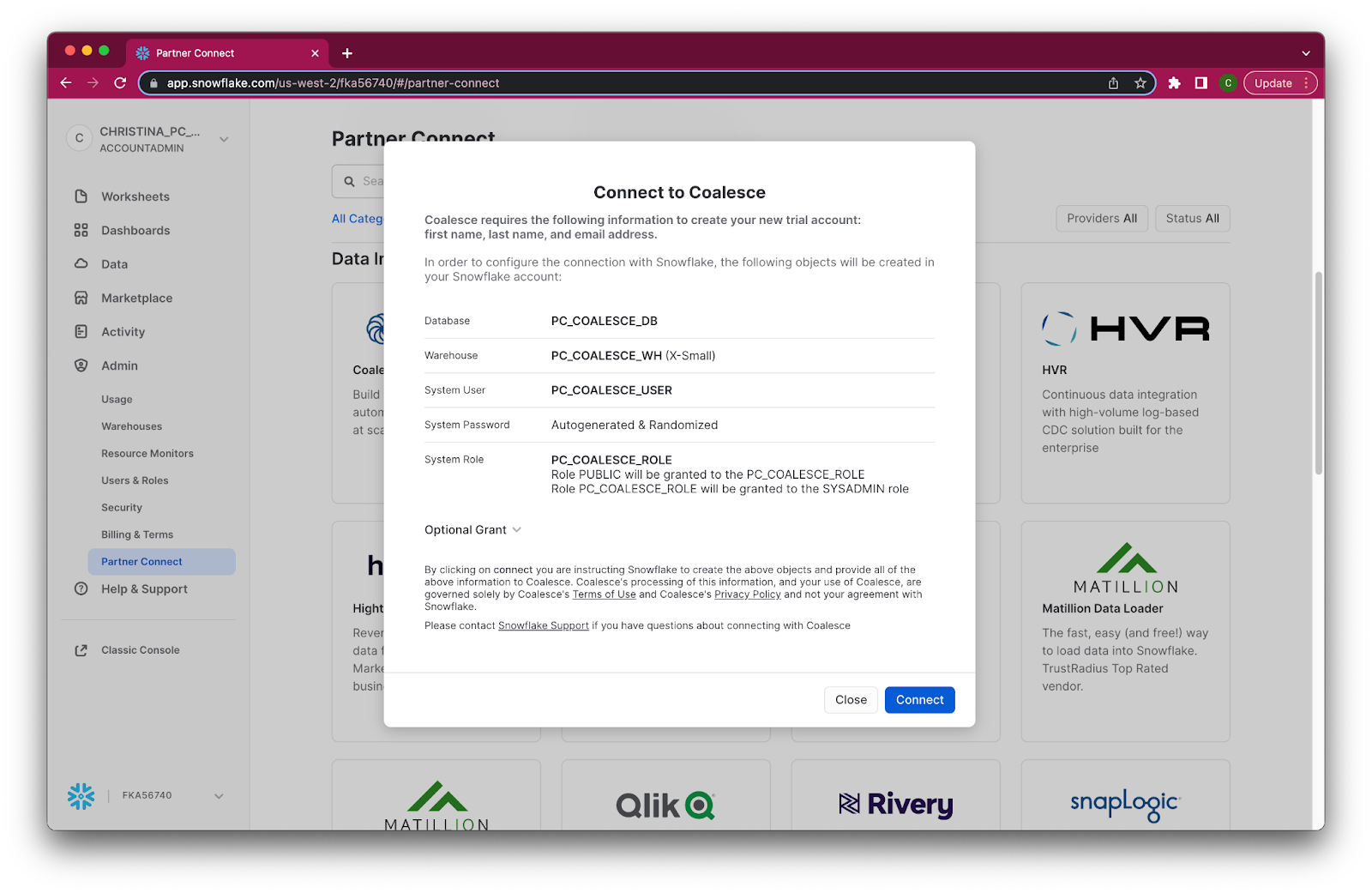
- When prompted, click Activate to activate your account. You can also activate your account later using the activation link emailed to your address.
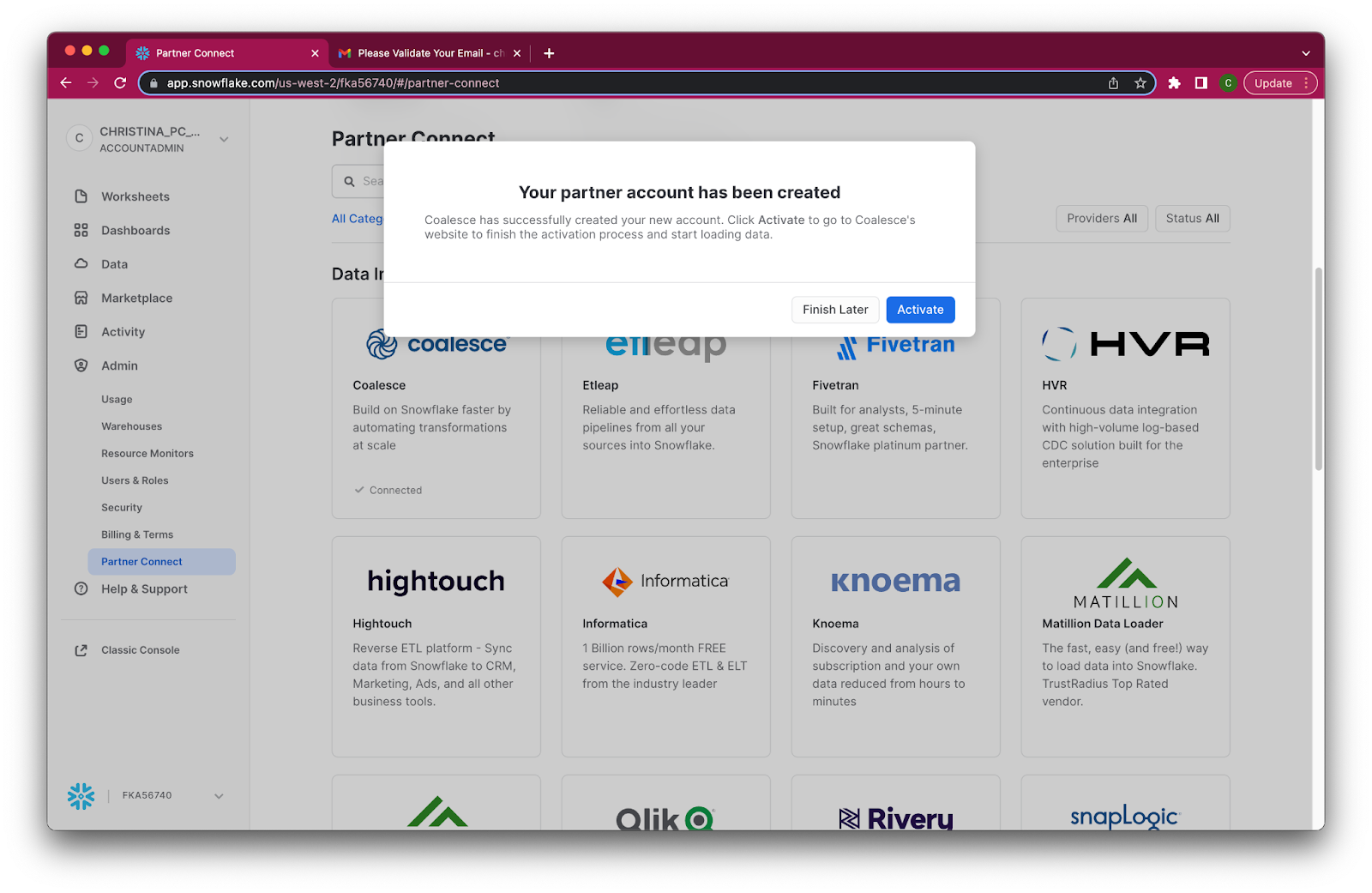
- Once you've activated your account, fill in your information to complete the activation process.
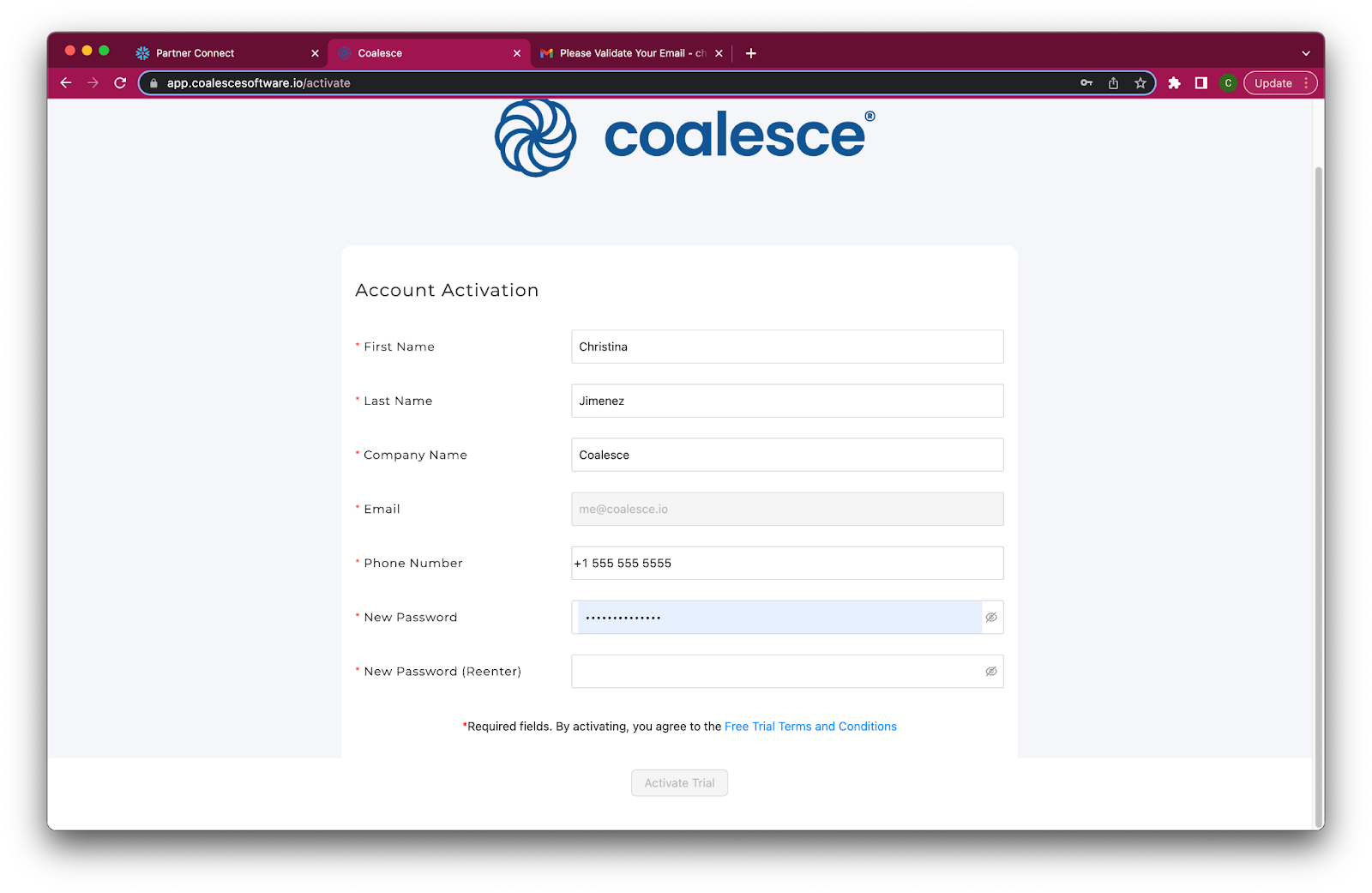
Congratulations! You've successfully created your Coalesce trial account.
Step 3: Set Up The Ski Store Dataset
- We will be using a M Warehouse size within Snowflake for this lab. You can upgrade this within the admin tab of your Snowflake account.
- In your Snowflake account, click on the Worksheets Tab in the left-hand navigation bar.

- Within Worksheets, click the "+" button in the top-right corner of Snowsight and choose "SQL Worksheet."
- Paste the setup SQL from below into the worksheet that you just created:
CREATE or REPLACE schema pc_coalesce_db.calls;
CREATE or REPLACE file format csvformat
SKIP_HEADER = 1
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
type = 'CSV';
CREATE or REPLACE stage pc_coalesce_db.calls.call_transcripts_data_stage
file_format = csvformat
url = 's3://sfquickstarts/misc/call_transcripts/';
CREATE or REPLACE table pc_coalesce_db.calls.CALL_TRANSCRIPTS (
date_created date,
language varchar(60),
country varchar(60),
product varchar(60),
category varchar(60),
damage_type varchar(90),
transcript varchar
);
COPY into pc_coalesce_db.calls.CALL_TRANSCRIPTS
from @pc_coalesce_db.calls.call_transcripts_data_stage;
Step 4: Add the Cortex Package from the Coalesce Marketplace
You will need to add the ML Forecast node into your Coalesce workspace in order to complete this lab.
- Launch your workspace within your Coalesce account
- Navigate to the build settings in the lower left hand corner of the left sidebar
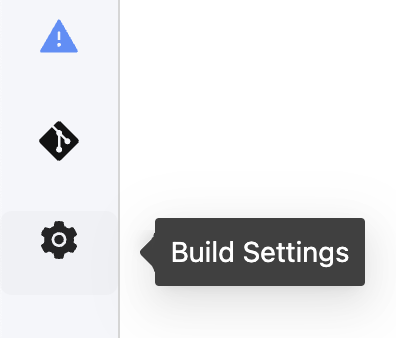
- Select Packages from the Build Settings options
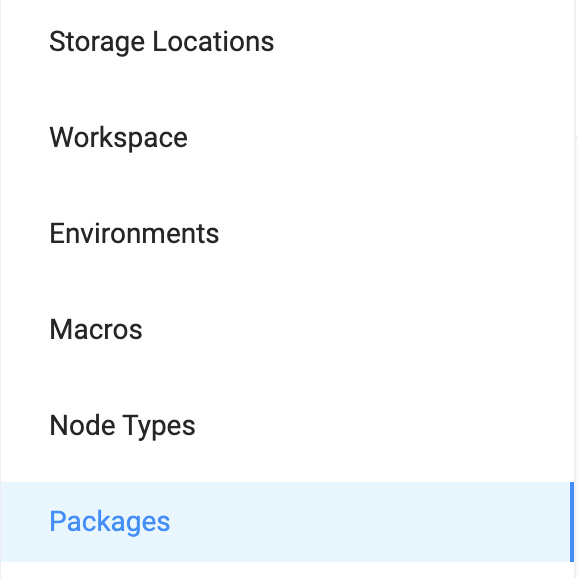
- Select Browse to Launch the Coalesce Marketplace
- Select Find out more within the Cortex package

- Copy the package ID from the Cortex page

- Back in Coalesce, select the Install button:

- Paste the Package ID into the corresponding input box:
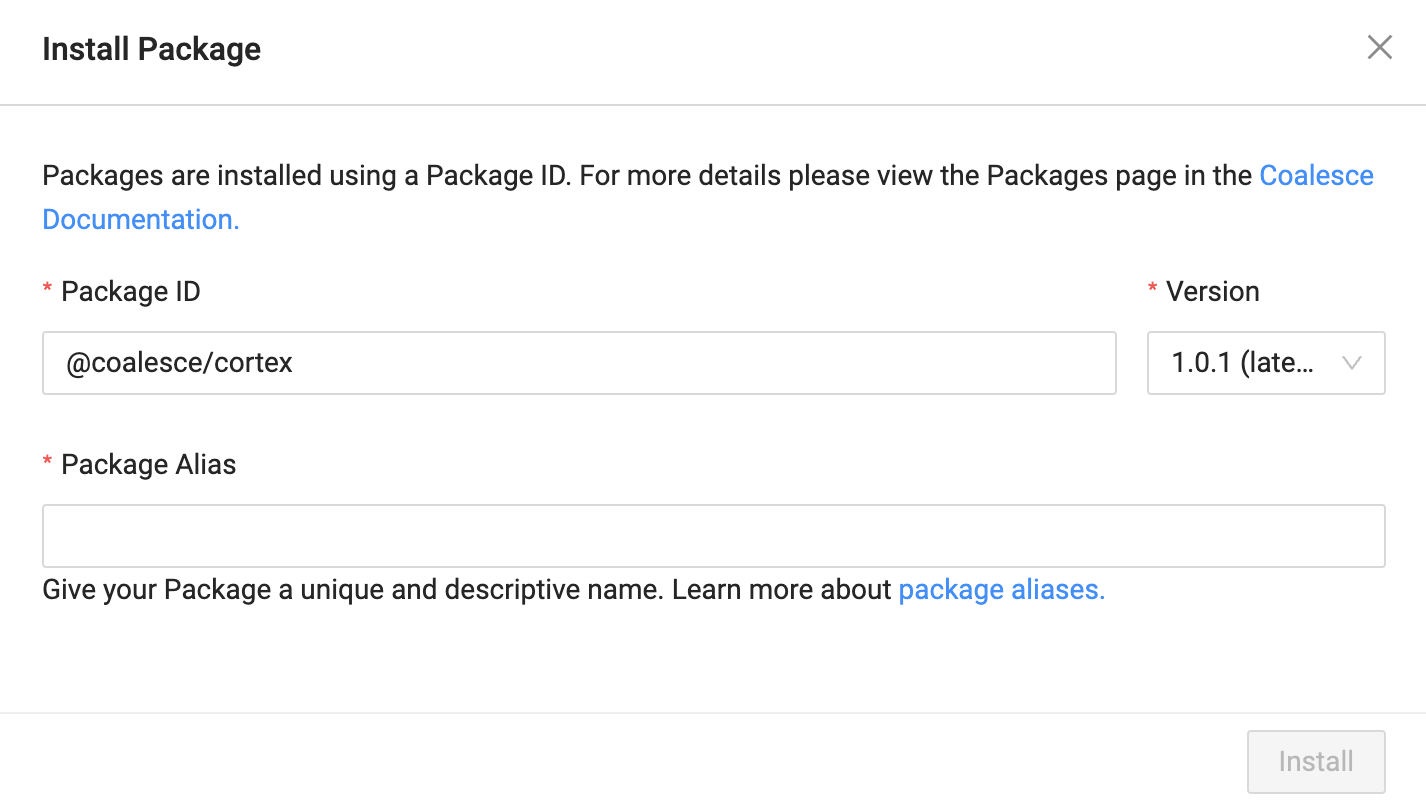
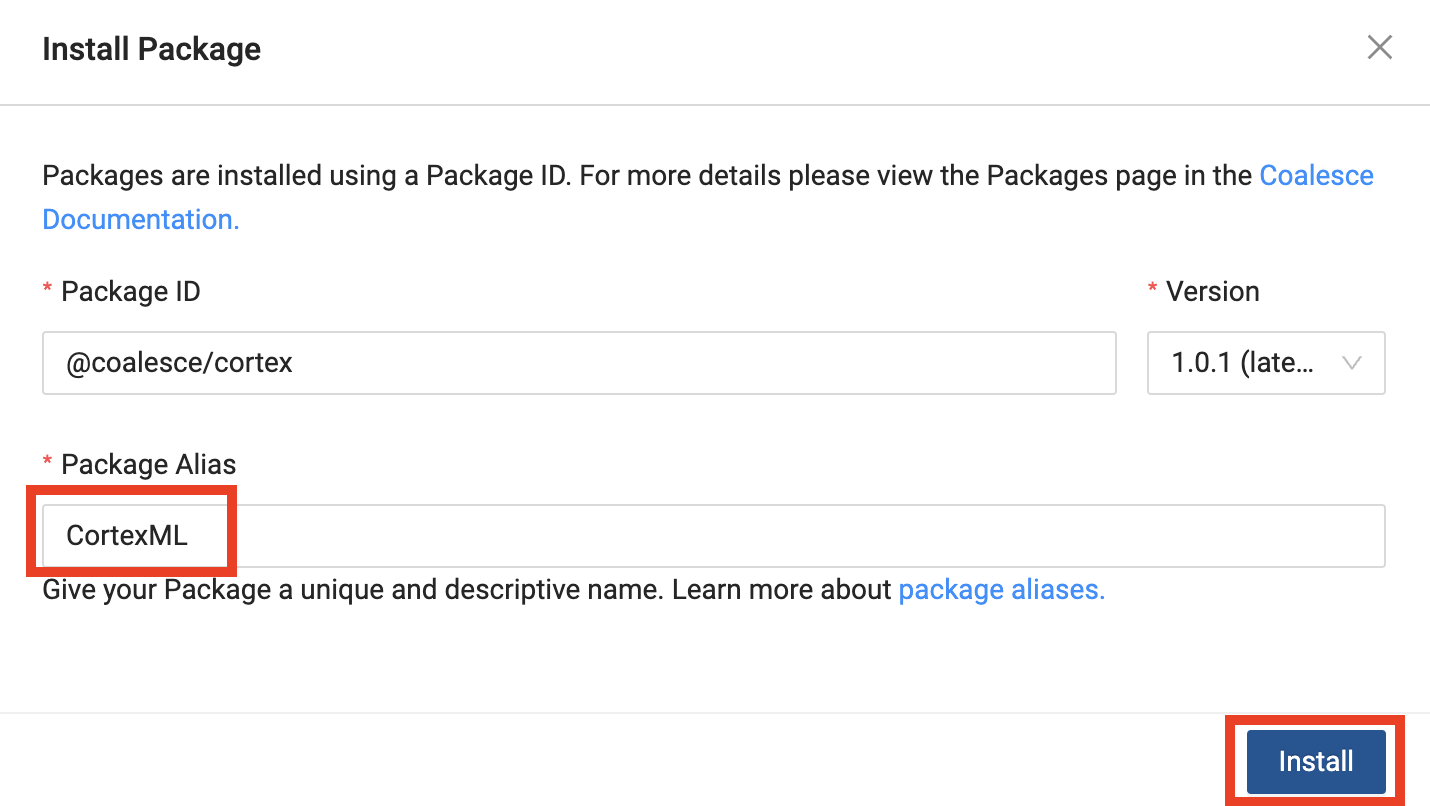
- Give the package an Alias, which is the name of the package that will appear within the Build Interface of Coalesce. And finish by clicking Install.
Let's get familiar with Coalesce by walking through the basic components of the user interface.
Once you've activated your Coalesce trial account and logged in, you will land in your Projects dashboard. Projects are a useful way of organizing your development work by a specific purpose or team goal, similar to how folders help you organize documents in Google Drive.
Your trial account includes a default Project to help you get started.
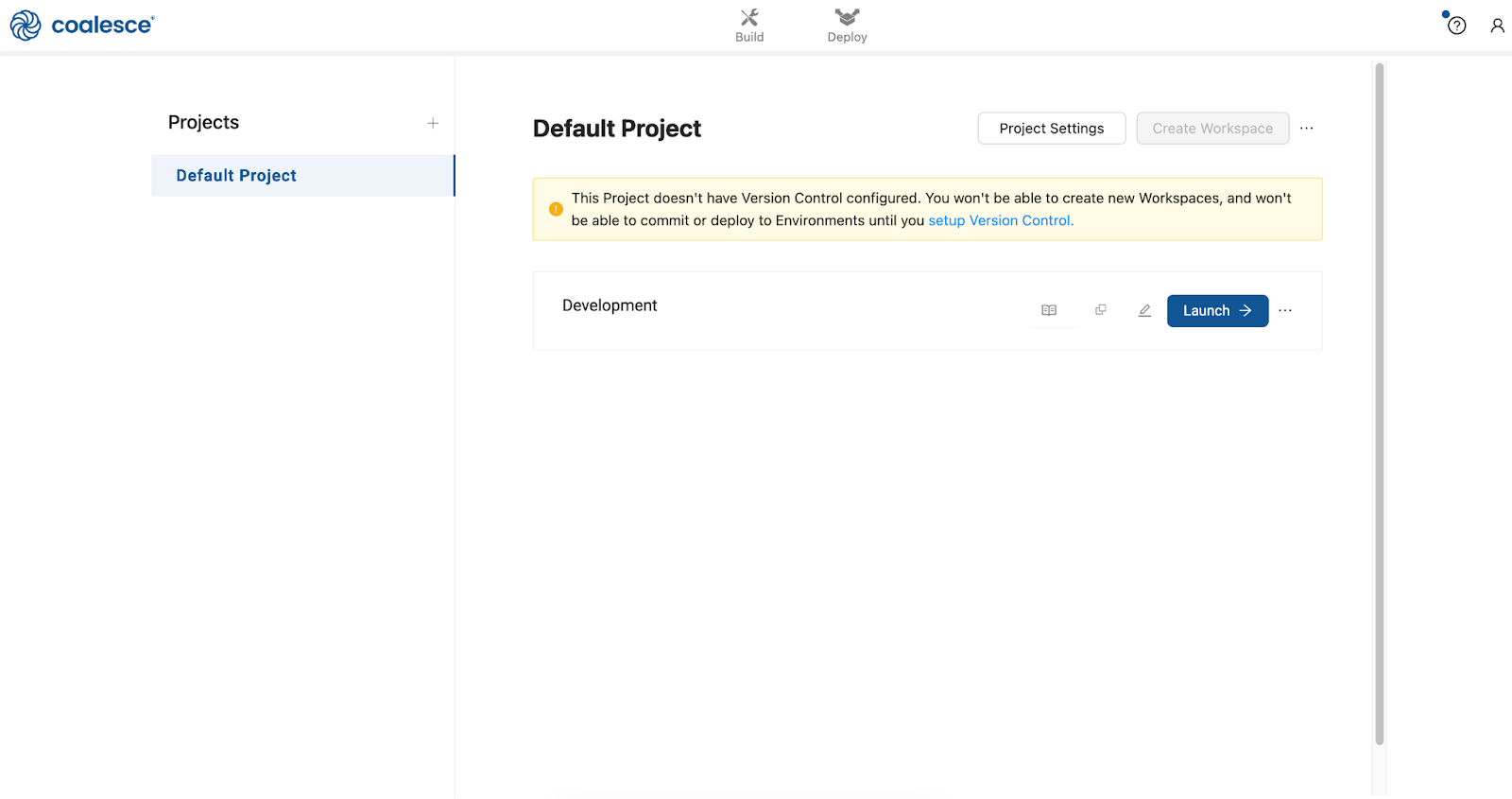
- Launch your Development Workspace by clicking the Launch button and navigate to the Build Interface of the Coalesce UI. This is where you can create, modify and publish nodes that will transform your data.
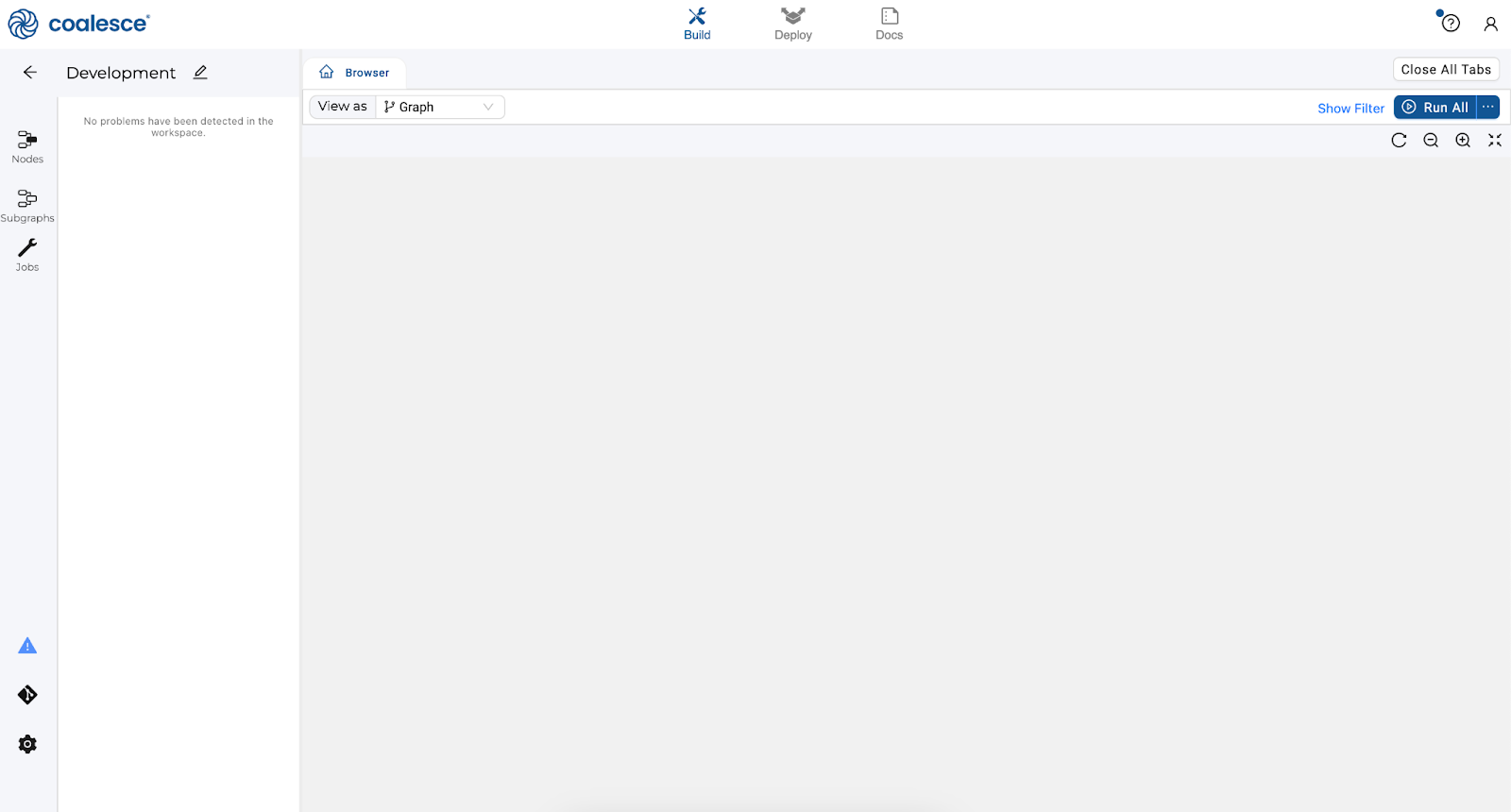
Nodes are visual representations of objects in Snowflake that can be arranged to create a Directed Acyclic Graph (DAG or Graph). A DAG is a conceptual representation of the nodes within your data pipeline and their relationships to and dependencies on each other.
- In the Browser tab of the Build interface, you can visualize your node graph using the Graph, Node Grid, and Column Grid views. In the upper right hand corner, there is a person-shaped icon where you can manage your account and user settings.
- By clicking the question mark icon, you can access the Resource Center to find product guides, view announcements, request support, and share feedback.
- The Browser tab of the Build interface is where you'll build your pipelines using nodes. You can visualize your graph of these nodes using the Graph, Node Grid, and Column Grid views. While this area is currently empty, we will build out nodes and our Graph in subsequent steps of this lab.
- Next to the Build interface is the Deploy interface. This is where you will push your pipeline to other environments such as Testing or Production.
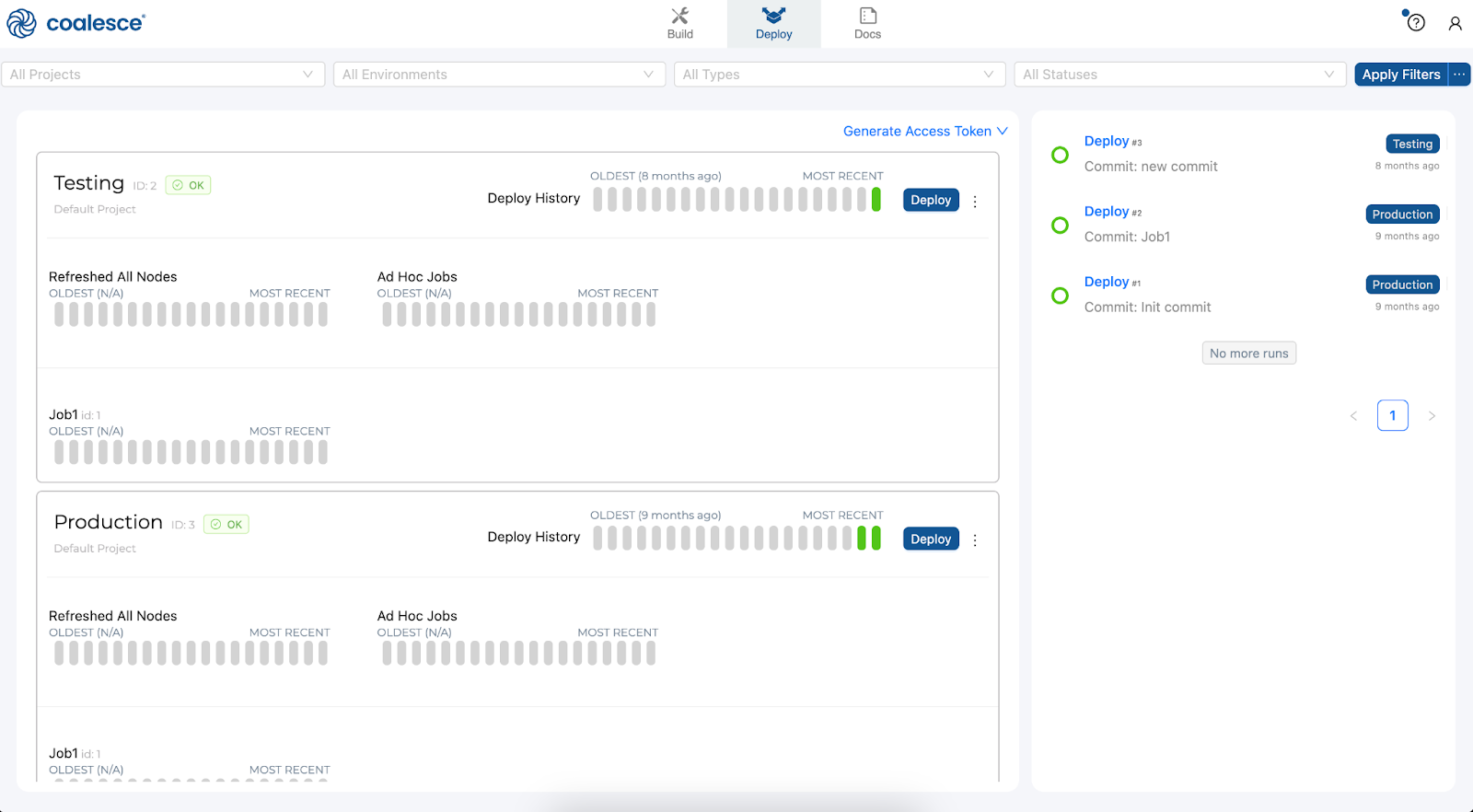
- Next to the Deploy interface is the Docs interface. Documentation is an essential step in building a sustainable data architecture, but is sometimes put aside to focus on development work to meet deadlines. To help with this, Coalesce automatically generates and updates documentation as you work.
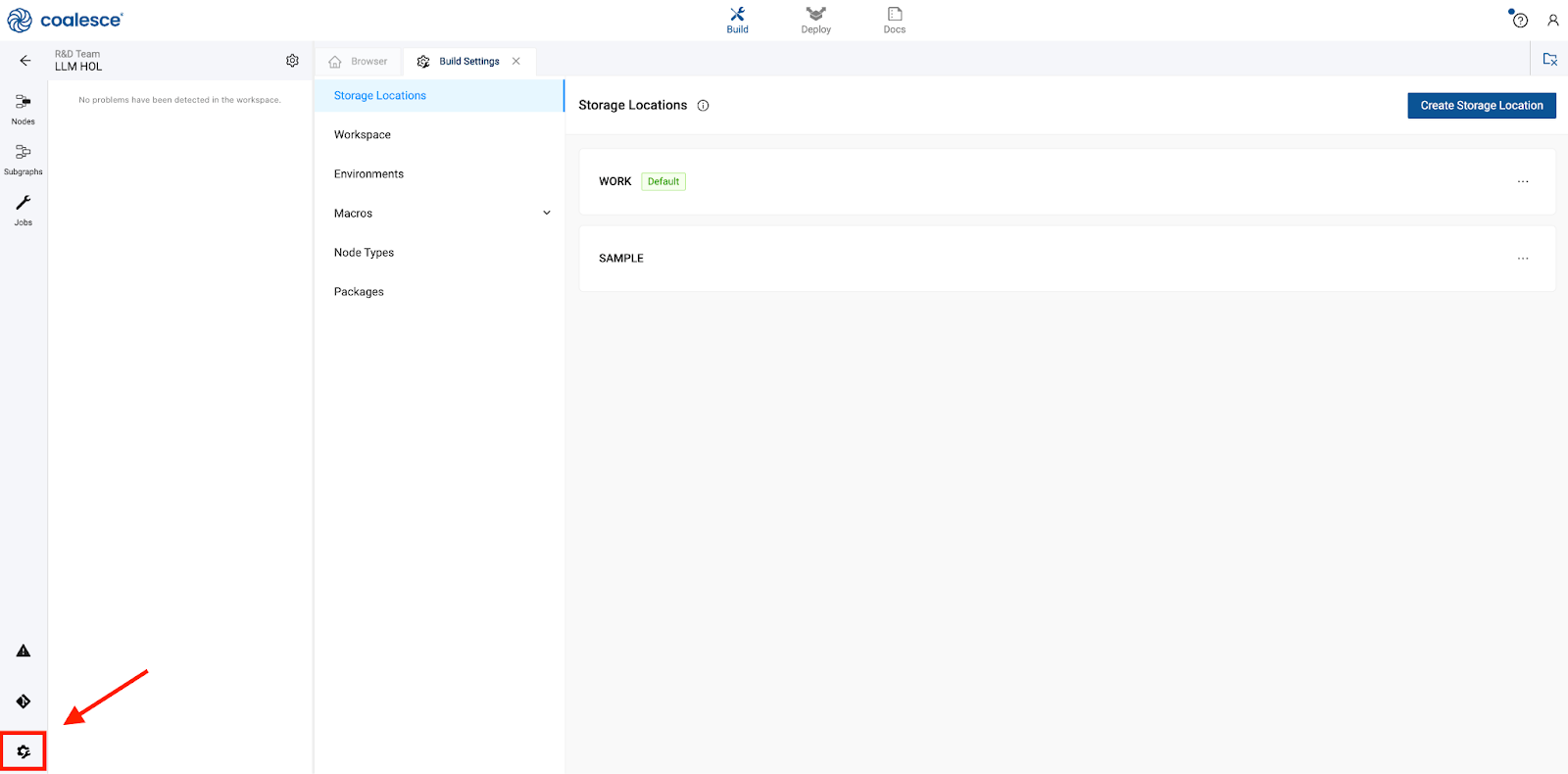
Before you can begin transforming your data, you will need to configure a storage location. Storage locations represent a logical destination in Snowflake for your database objects such as views and tables.
- To add a storage location, navigate to the left side of your screen and click on the Build settings cog.
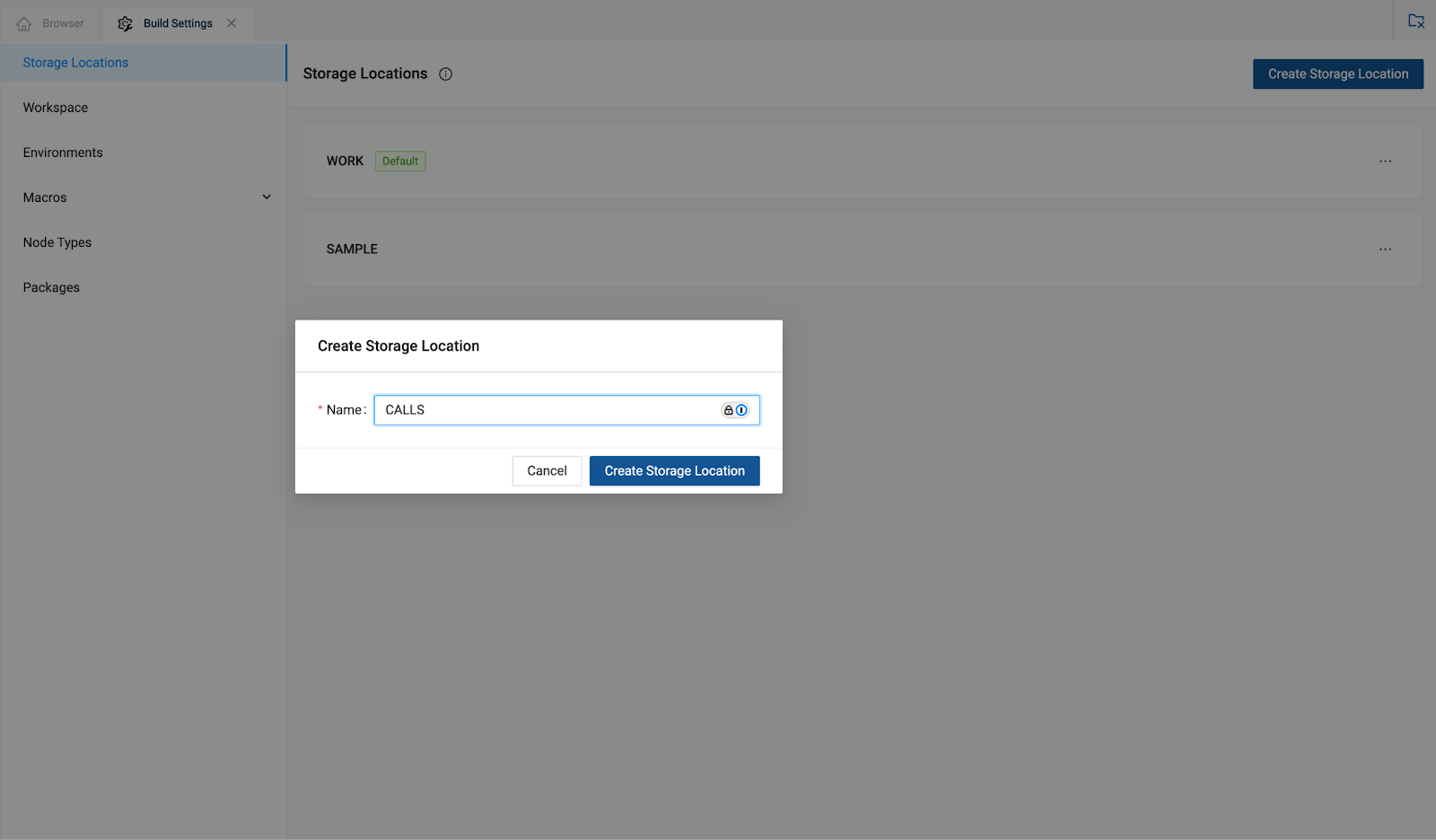
- Click the "Add New Storage Locations" button and name it
CALLSfor your call transcript data.
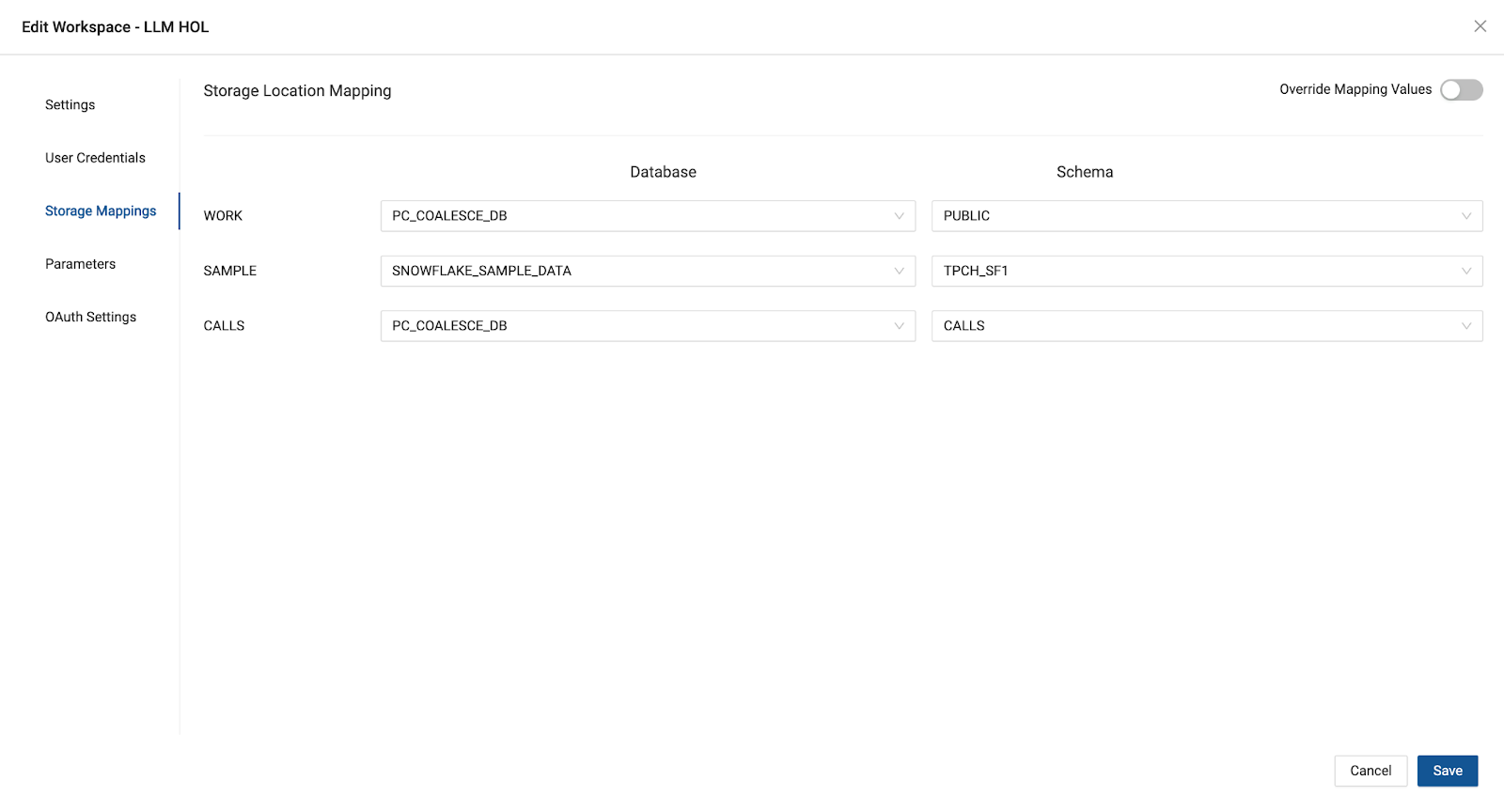
- Now map your storage locations to their physical destinations in Snowflake. In the upper left corner next to your Workspace name, click on the gear icon to open your Workspace settings. Click on Storage Mappings and map your
CALLlocation to thePC_COALESCE_DBdatabase and theCALLSschema.
- Click save, and you have successfully configured your new storage location to provide Coalesce to work with the call transcript data.
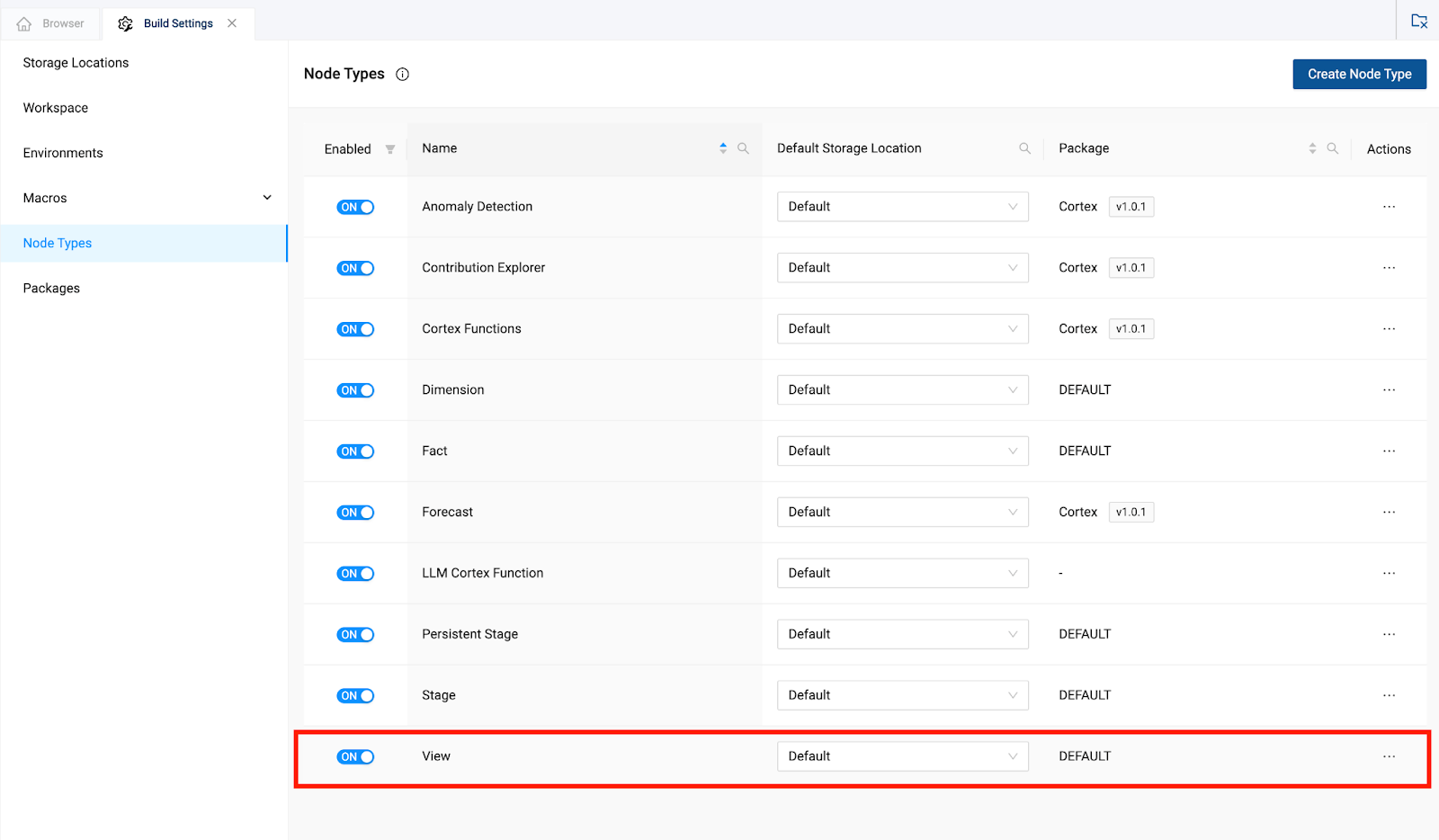
- In the Build settings of the workspace, navigate to Node Types and toggle on View.
Let's start to build the foundation of your LLM data pipeline by creating a Graph (DAG) and adding data in the form of Source nodes.
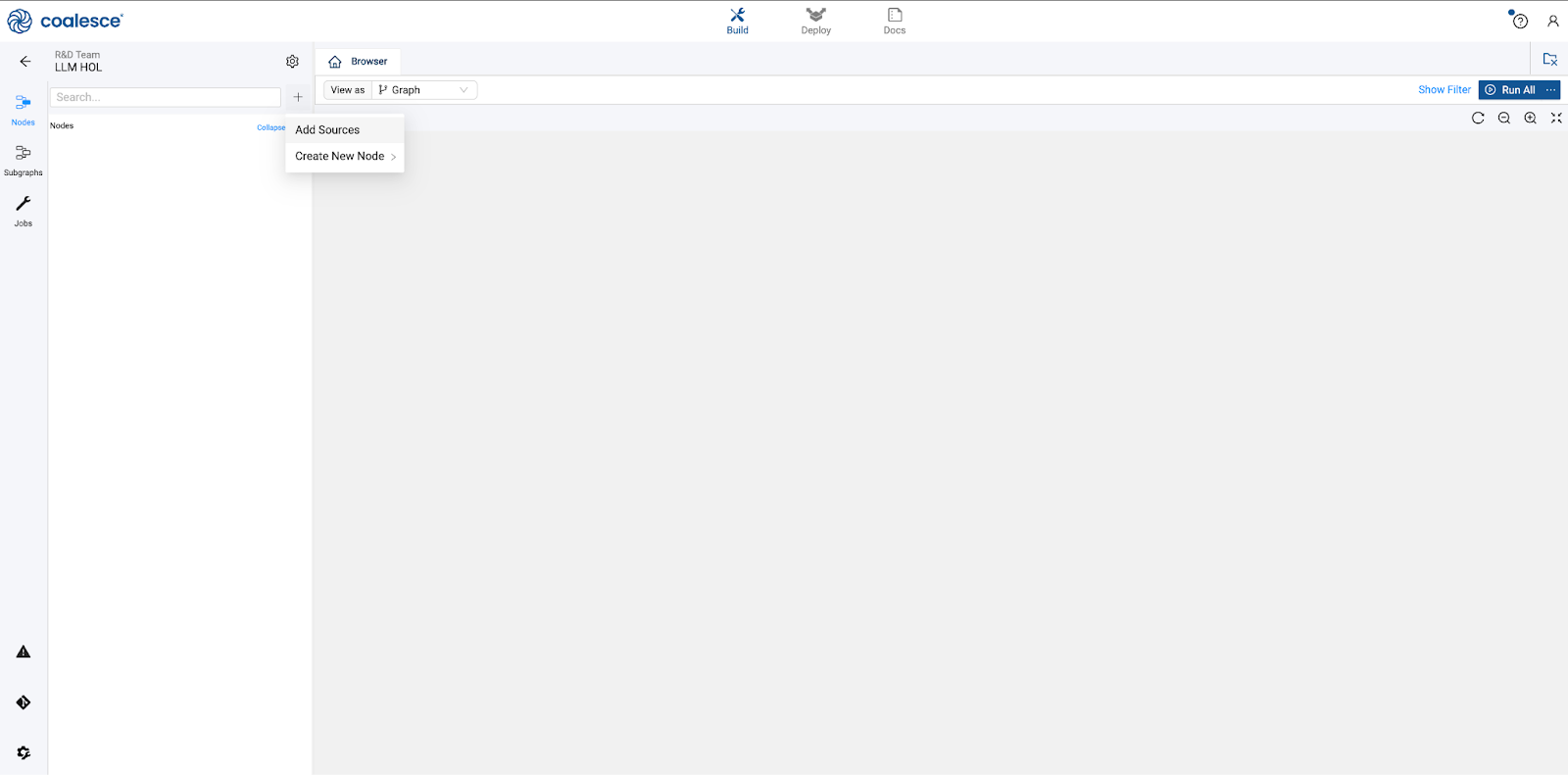
- Start in the Build interface and click on Nodes in the left sidebar (if not already open). Click the + icon and select Add Sources.
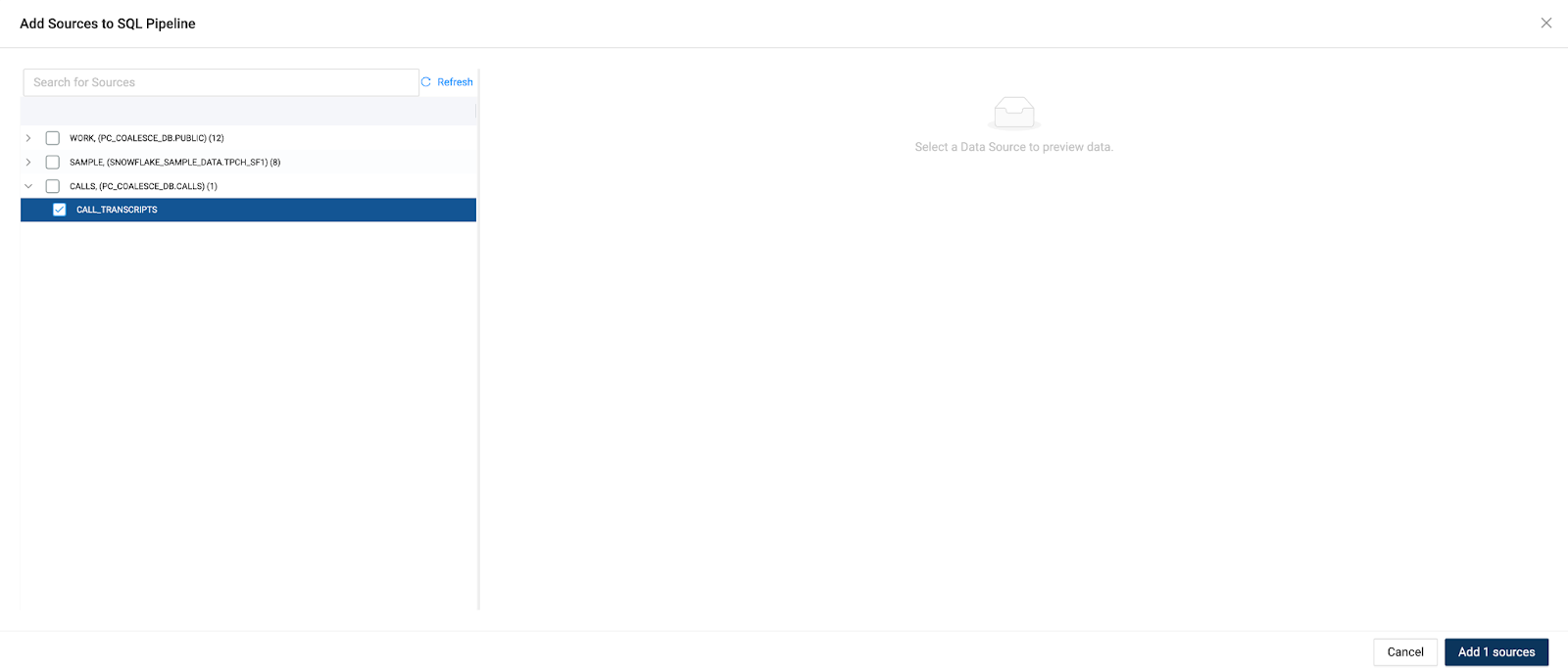
- Select the
CALL_TRANSCRIPTStable from theCALLSsource storage location. Then click the Add 1 Sources button.
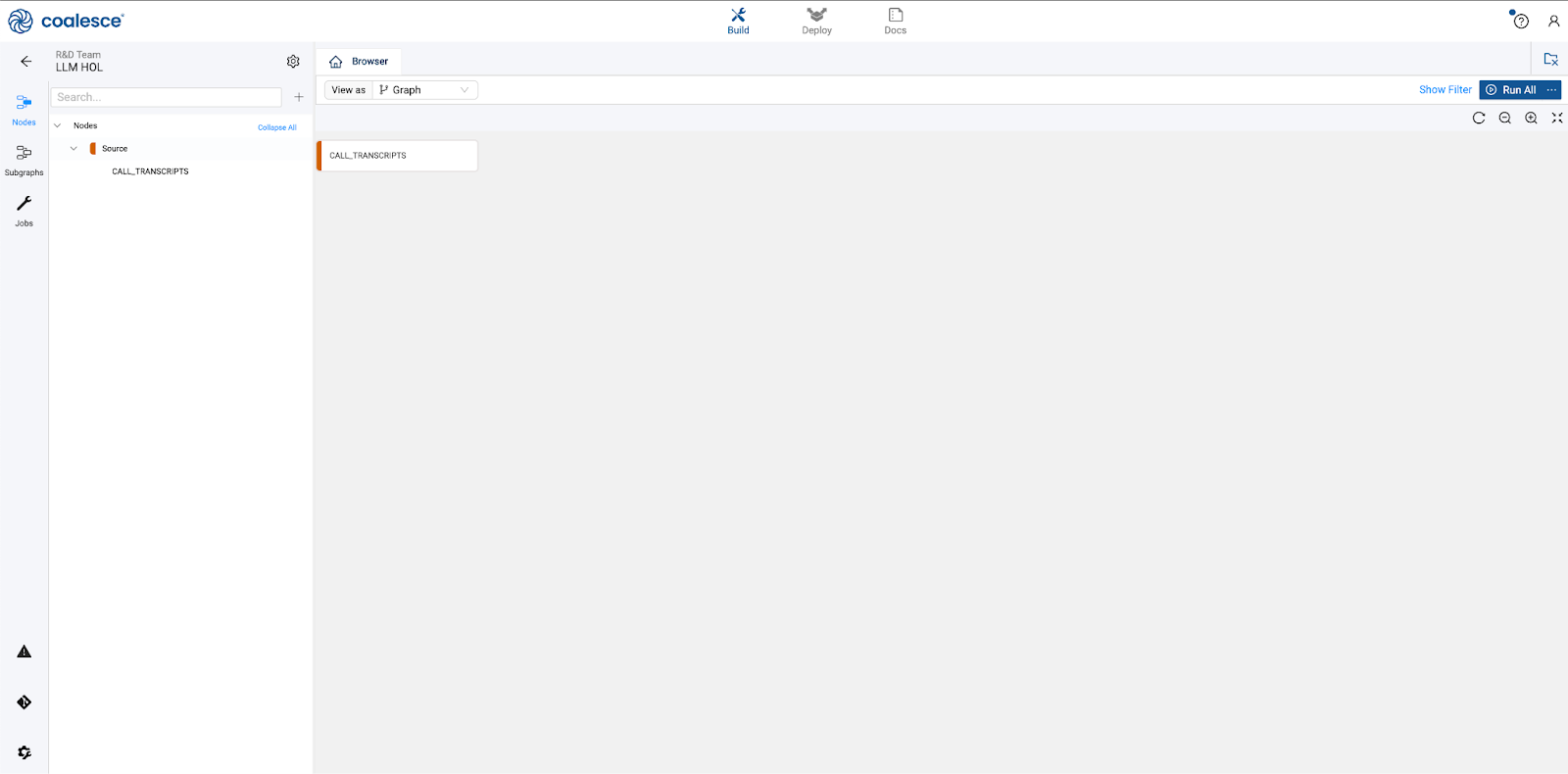
- You'll now see your graph populated with your Source node. Note that the node is designated in red. Each node type in Coalesce has its own color associated with it, which helps with visual organization when viewing a Graph.
Now that you've added your Source node, let's prepare the data by adding business logic with Stage nodes. Stage nodes represent staging tables within Snowflake where transformations can be previewed and performed. Let's start by adding a standardized "stage layer" for the data source.
- Select the
CALL_TRANSCRIPTsource node then right click and select Add Node > Stage from the drop down menu. This will create a new stage node and Coalesce will automatically open the mapping grid of the node for you to begin transforming your data.
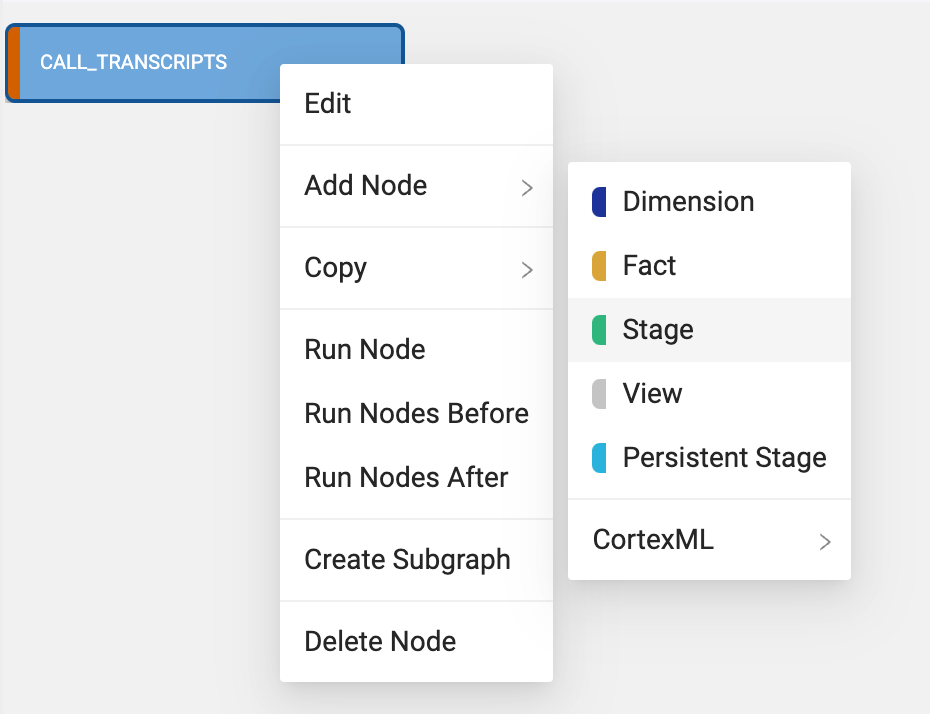
- Within the Node, the large middle section is your Mapping grid, where you can see the structure of your node along with column metadata like transformations, data types, and sources.
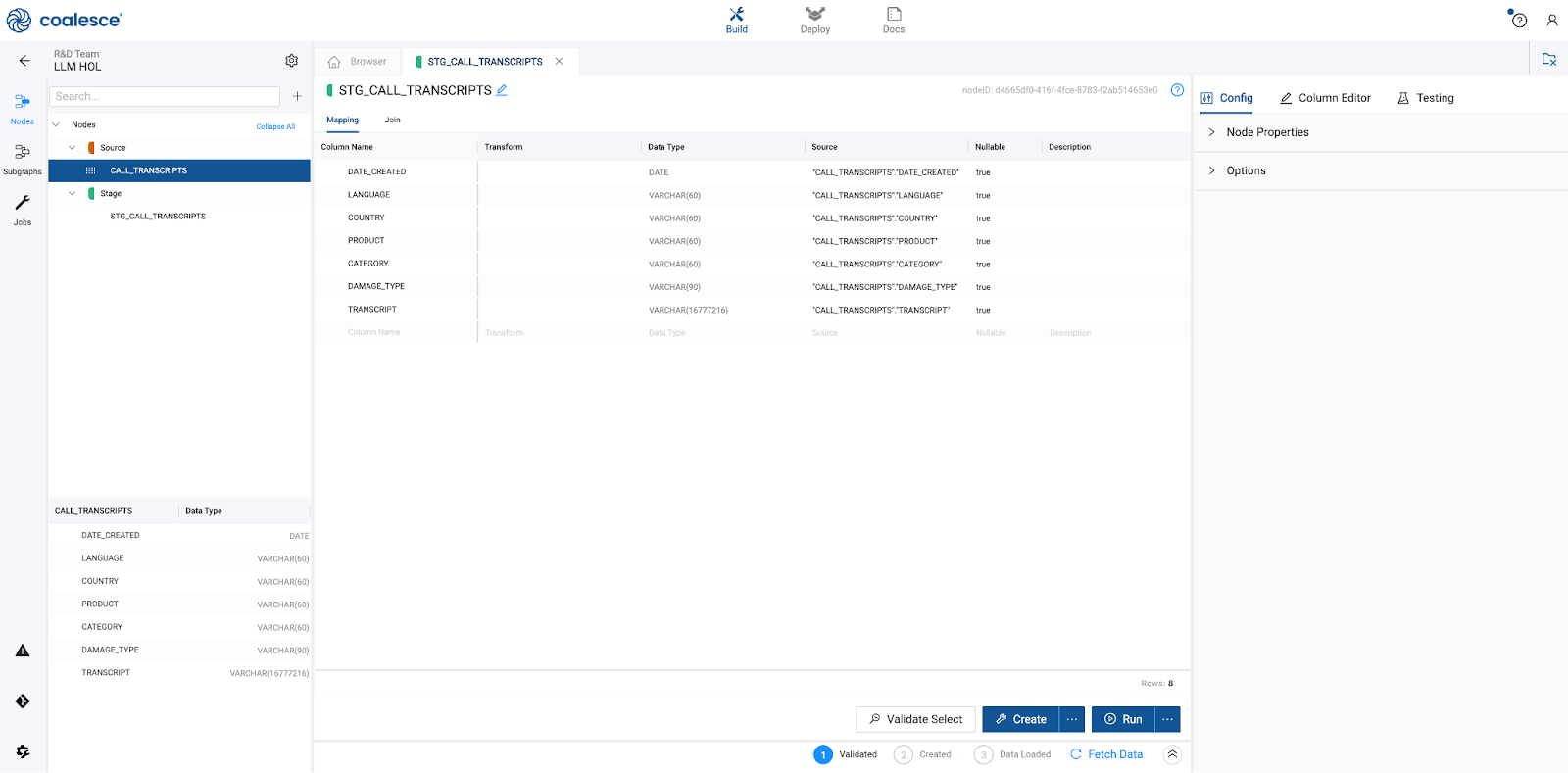
- On the right hand side of the Node Editor is the Config section, where you can view and set configurations based on the type of node you're using.

- At the bottom of the Node Editor, press the arrow button to view the Data Preview pane.
- Rename the node to
STG_CALL_TRANSCRIPTS_GERMAN

- Within Coalesce, you can use the Transform column to write column level transformations using standard Snowflake SQL. We will transform the Category column to use an upper case format using the following function:
UPPER({{SRC}})
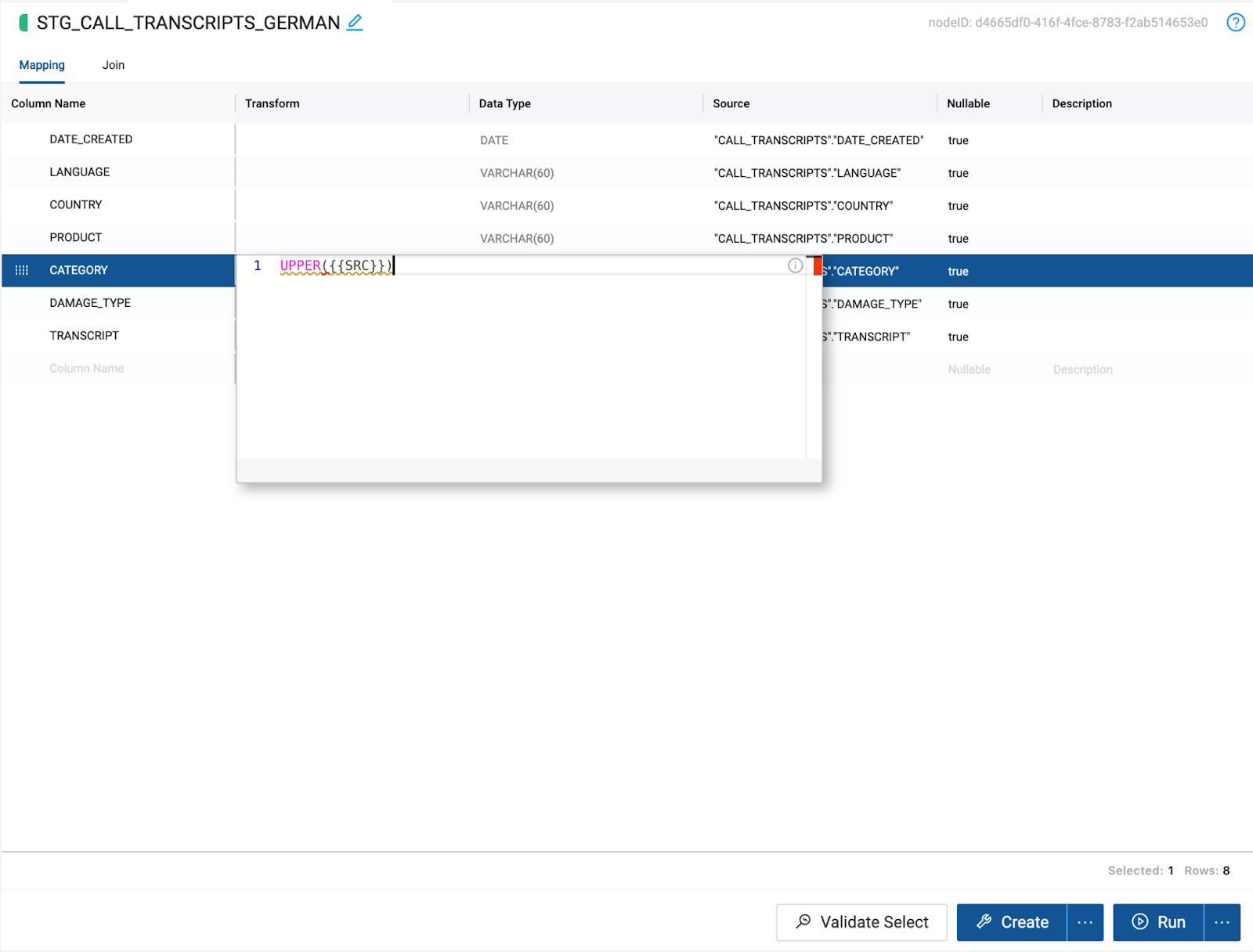
- Coalesce also allows you to write as much custom SQL as needed for your business use case. In this case, we need to process French and German language records in separate tables so that we can pass each language to its own Cortex translation function and union the tables together.
To do this, navigate to the Join tab, where you will see the node dependency listed within the Ref function. Within the Join tab, we can write any Snowflake supported SQL. In this use case, we will add a filter to limit our dataset to only records with German data, using the following code snippet:
WHERE "LANGUAGE" = 'German'
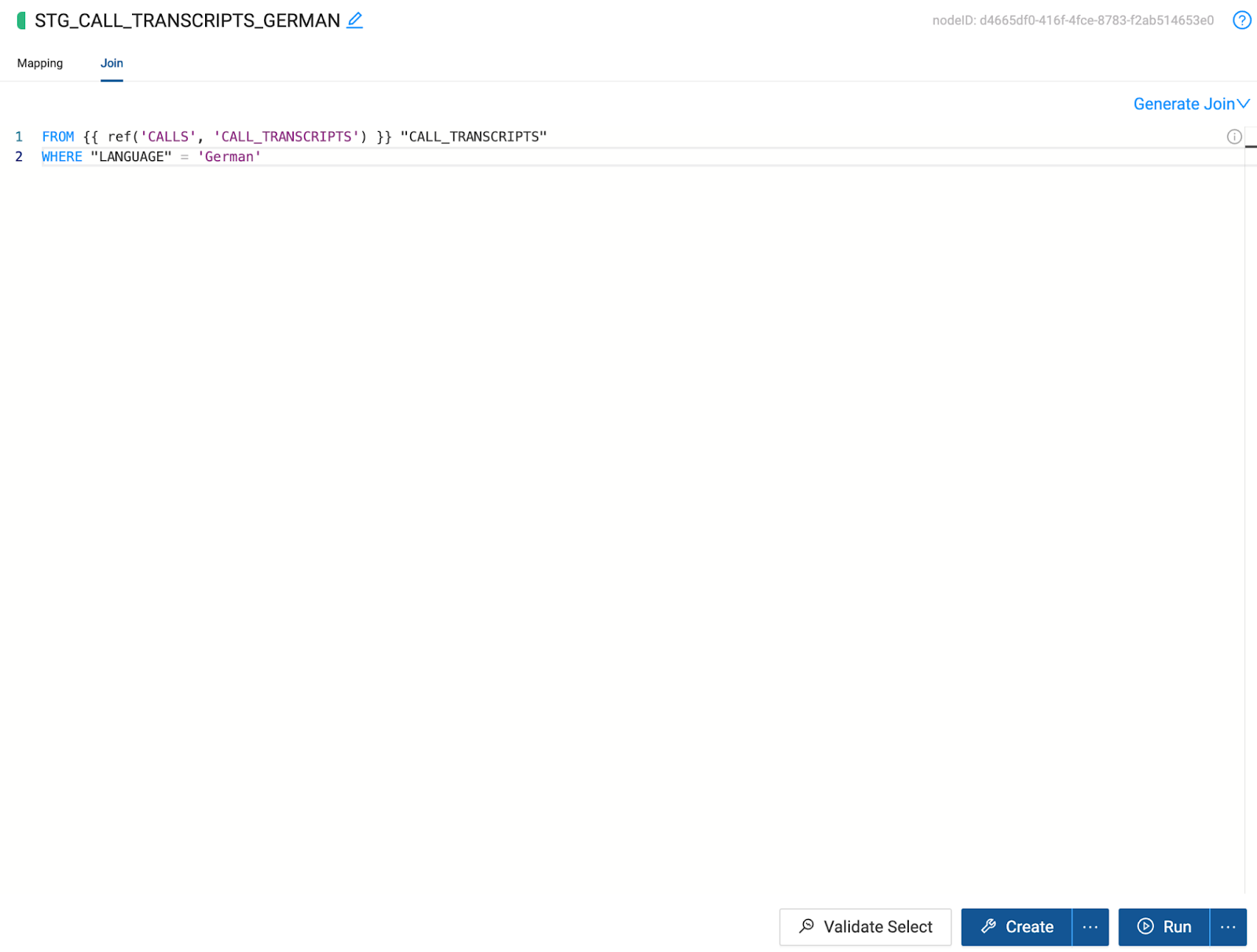
- Now that we have transformed and filtered the data for our German node, we now need to process our French data. Coalesce leverages metadata to allow users to quickly and easily build objects in Snowflake. Because of this metadata, users can duplicate existing objects, allowing everything contained in one node to be duplicated in another, including SQL transformations.
Navigate back to the Build Interface and right click on the STG_CALL_TRANSCRIPTS_GERMAN node and select duplicate node.
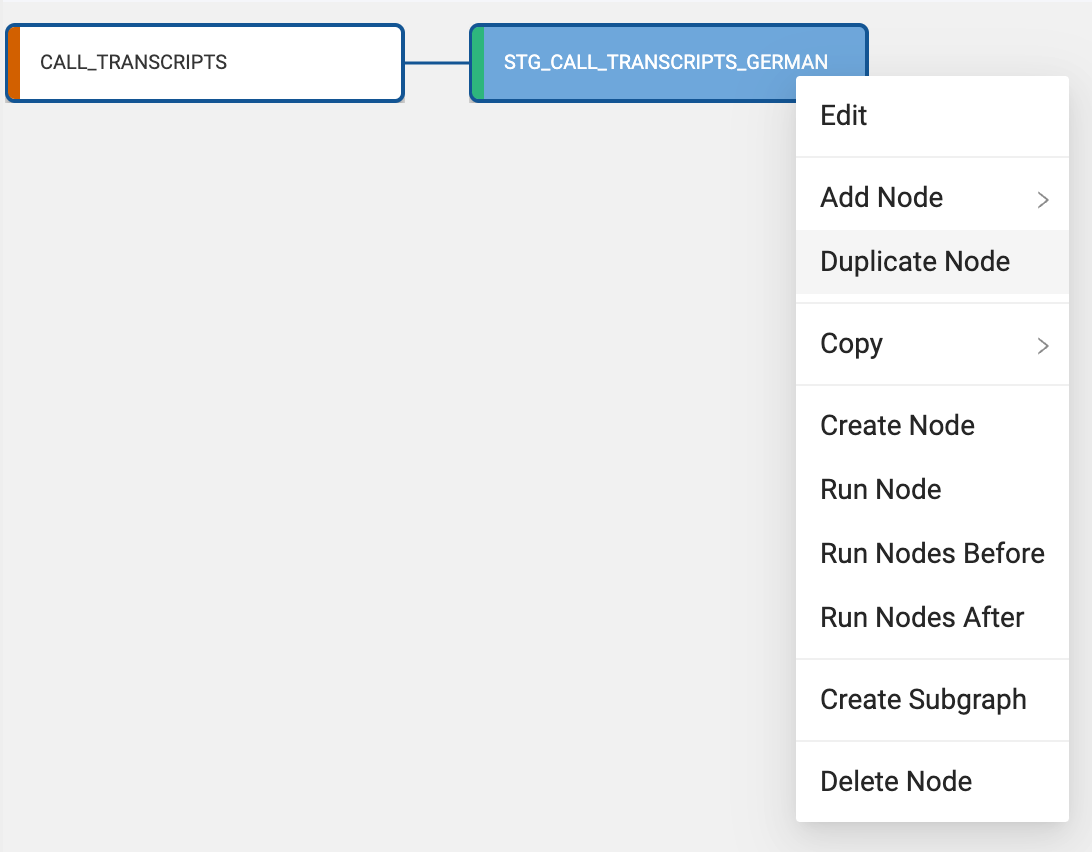
- Double click on the duplicated node, and once inside the node, rename the node to
STG_CALL_TRANSCRIPTS_FRENCH.

- Navigate to the Join tab, where we will update the where condition to an IN to include both French and English data.
WHERE "LANGUAGE" IN ('French', 'English')
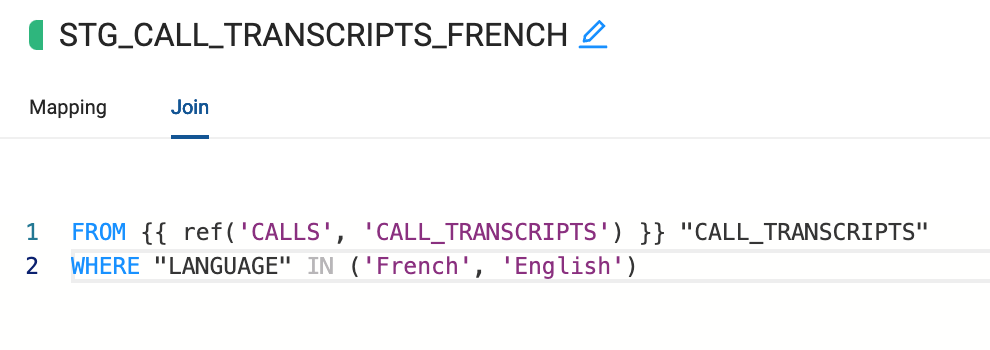
- All the changes made from the
STG_CALL_TRANSCRIPTS_GERMANcarry over into this node, so we don't need to rewrite any of our transformations. Let's change the view back to Graph and select Create All and then Run All

Now that we have prepared the call transcript data by creating nodes for each language, we can now process the language of the transcripts and translate them into a singular language. In this case, English.
- Select the
STG_CALL_TRANSCRIPTS_GERMANnode and hold the Shift key and select theSTG_CALL_TRANSCRIPTS_FRENCHnode. Right click on either node and navigate to Add Node. You should see the Cortex package that you installed from the Coalesce Marketplace. By hovering over the Cortex package, you should see the available nodes. Select Cortex Functions. This will add the Cortex Function node to eachSTGnode.
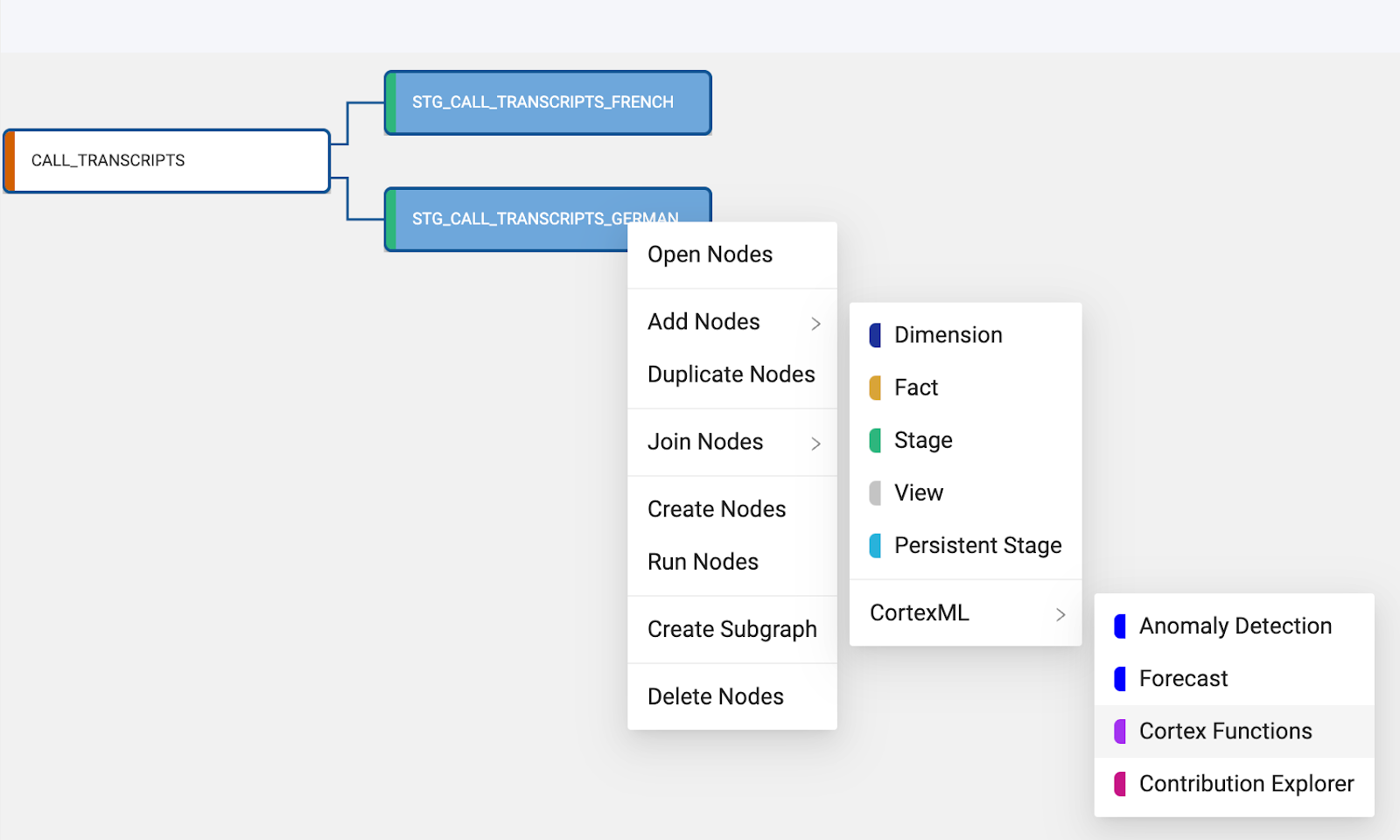
- You now need to configure the Cortex Function nodes to translate the language of the transcripts. Double click on the
LLM_CALL_TRANSCRIPTS_GERMANnode to open it.
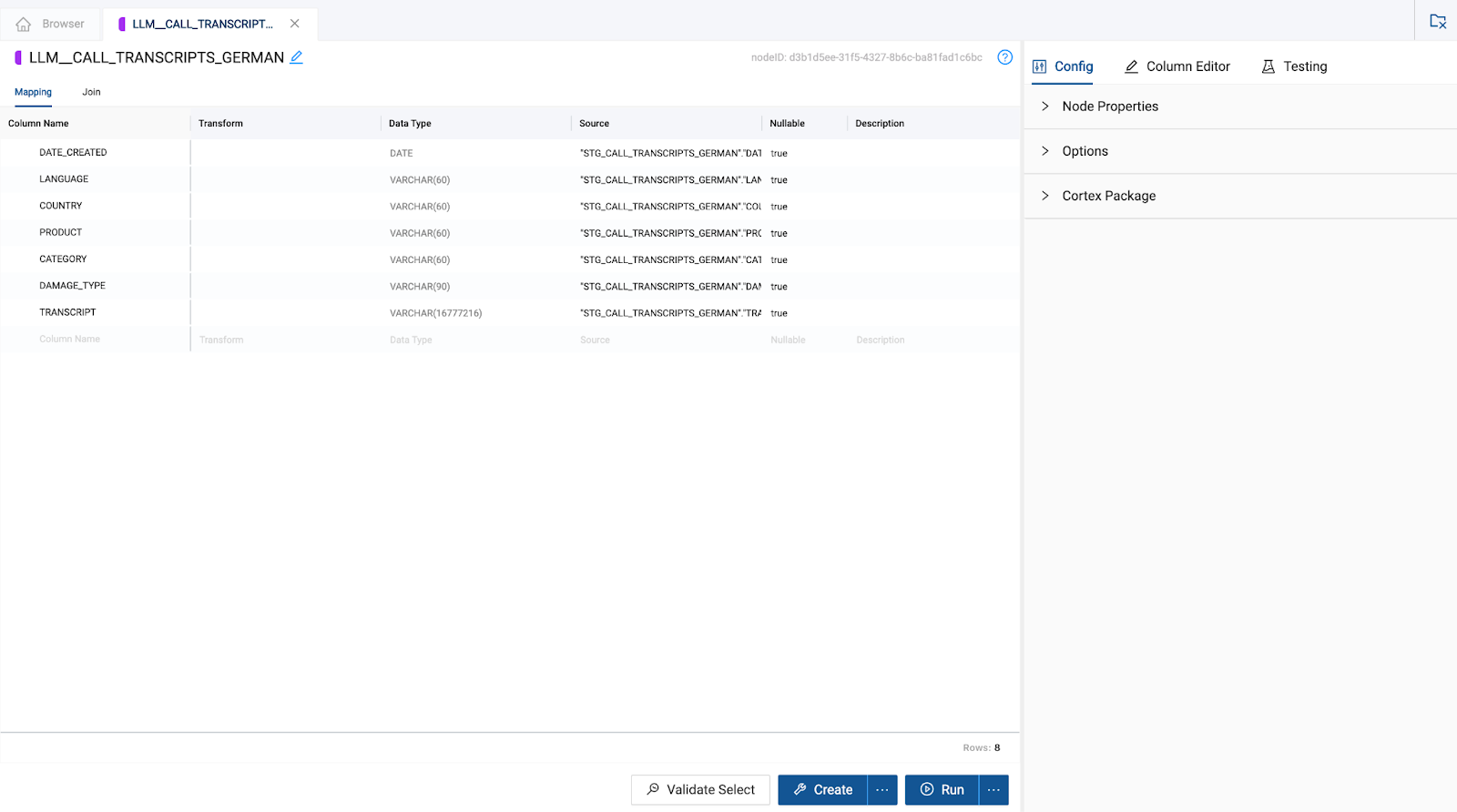
- In the configuration options on the right hand side of the node, open the Cortex Package dropdown and toggle on
TRANSLATE.
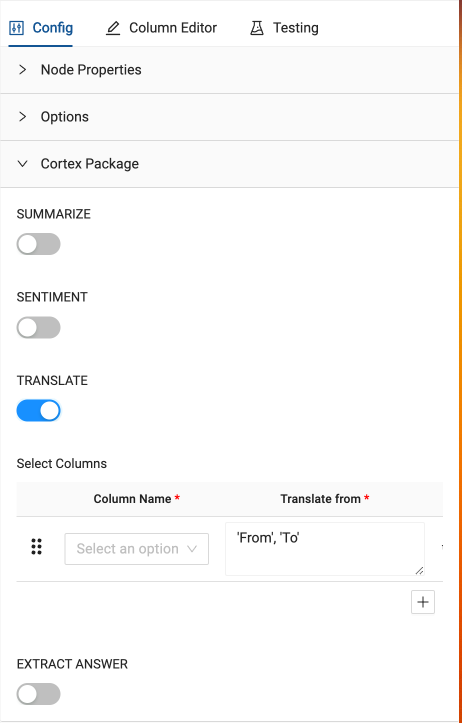
- With the
TRANSLATEtoggle on, In the column name selector dropdown, you need to select the column to translate. In this case, theTRANSCRIPTcolumn.
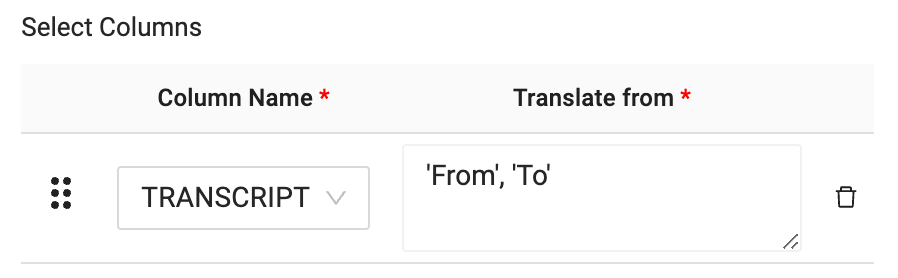
- Now that you have selected the column that will be translated, you will pass through the language you wish to translate from and the language you wish to translate to, into the translation text box. In this case, you want to translate from German to English. The language code for this translation is as follows:
'de', 'en'
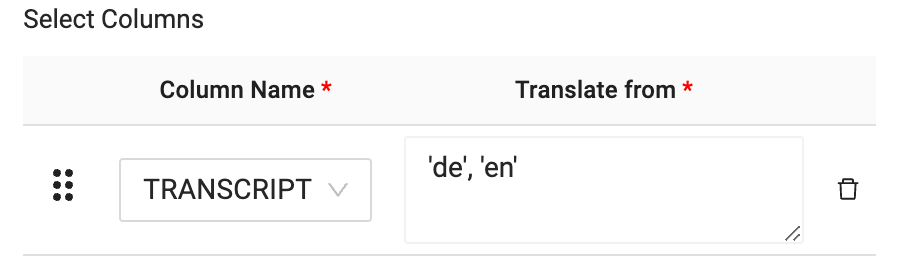
- Now that you have configured the LLM node to translate German data to English, you can click Create and Run to build the table in Snowflake and populate it with data.
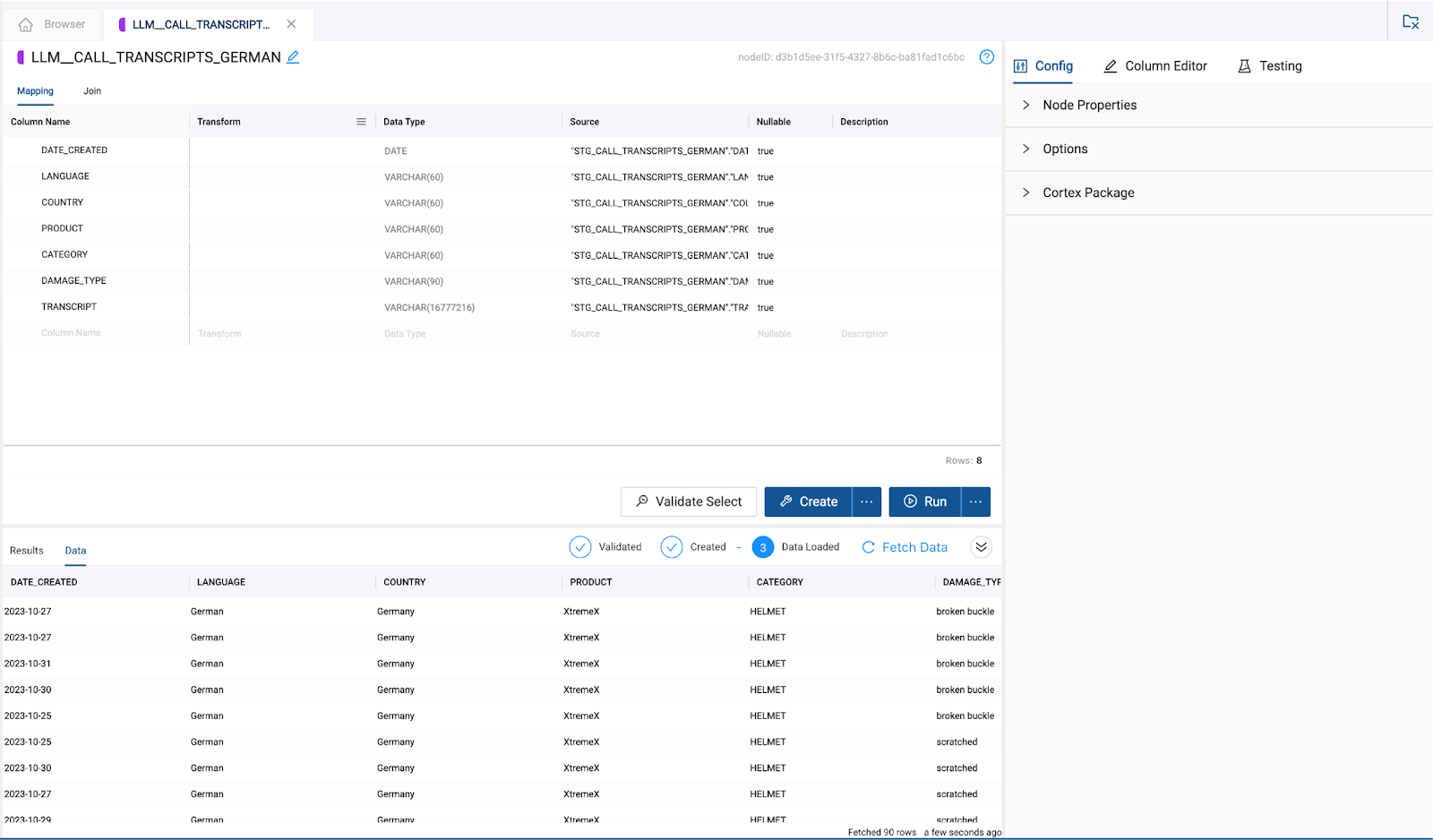
- While the
LLM_CALL_TRANSCRIPT_GERMANnode is running, you can configure theLLM_CALL_TRANSCRIPT_FRENCH. Double click on theLLM_CALL_TRANSCRIPT_FRENCHnode to open it.
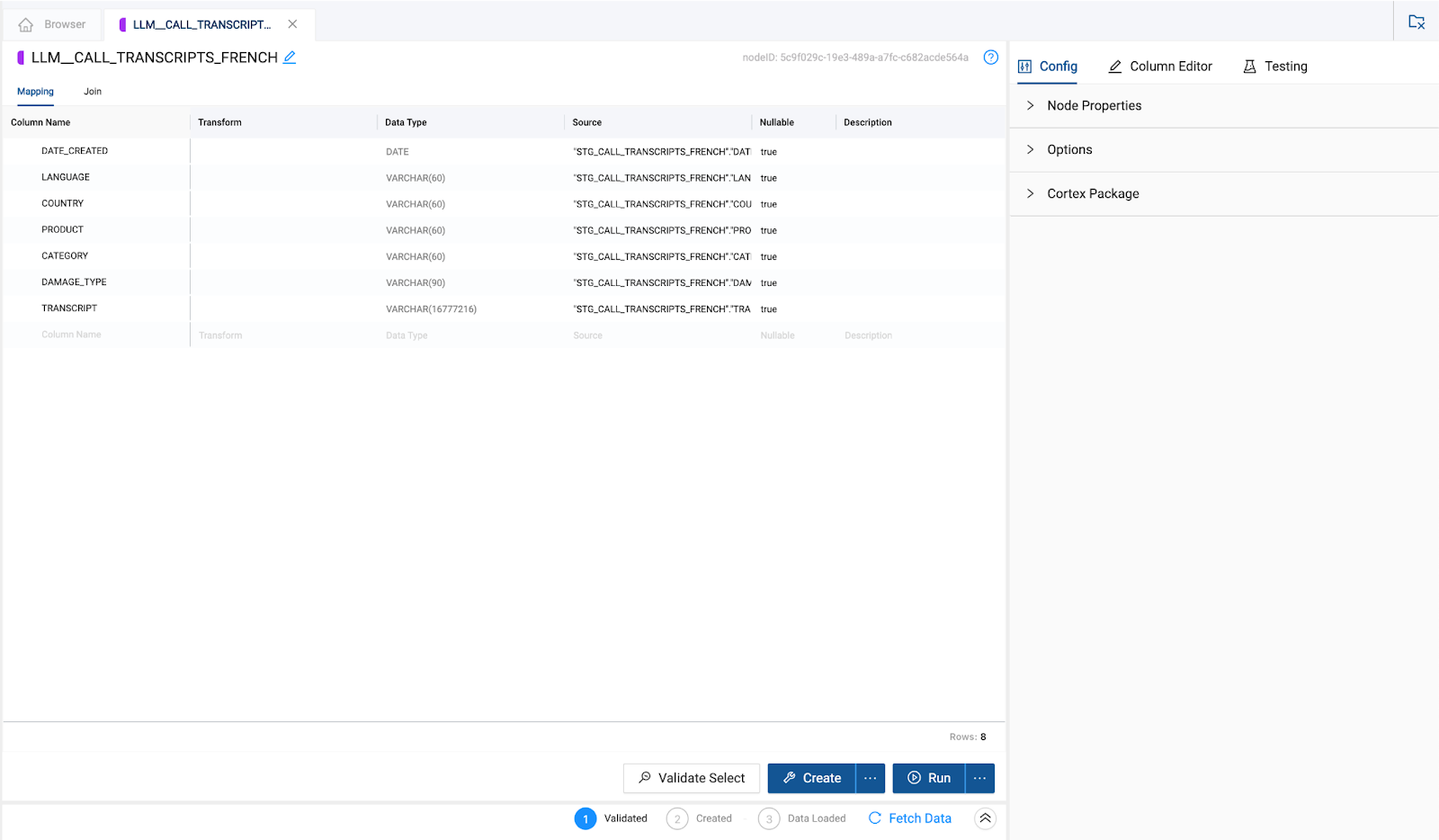
- Open the Cortex Package dropdown on the right hand side of the node and toggle on
TRANSLATE.
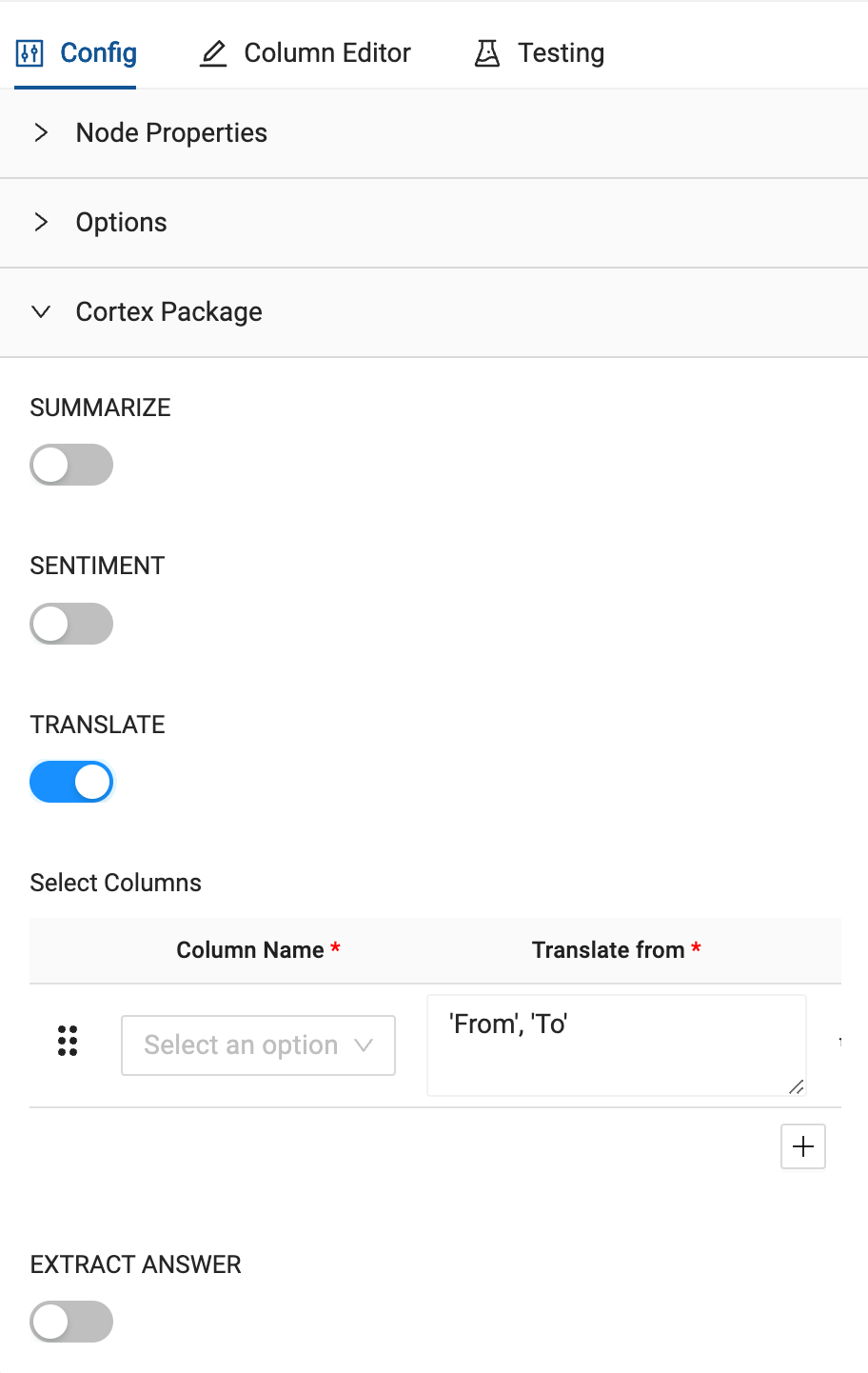
- Just like the German node translation, you will pass the
TRANSCRIPTcolumn through as the column you want to translate.
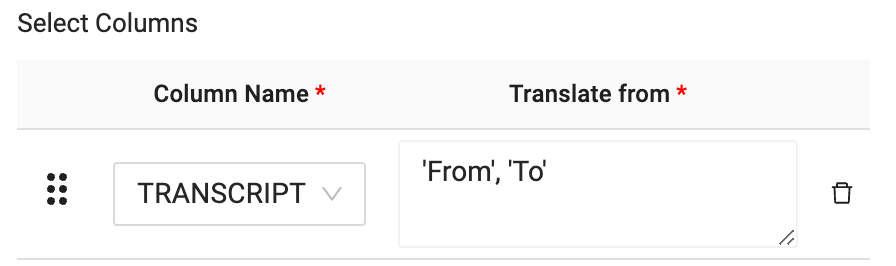
- Finally, you will configure the language code for what you wish to translate the language of the transcript column from to the language you wish to translate to. In this case, the language code is as follows:
'fr', 'en'
Any values in the transcript field which do not match the language being translated from will be ignored. In this case, there are both French and English language values in the TRANSCRIPT field. Because the English values are not in French, they will automatically pass through as their original values. Since those values are already in English, they don't require any additional processing.
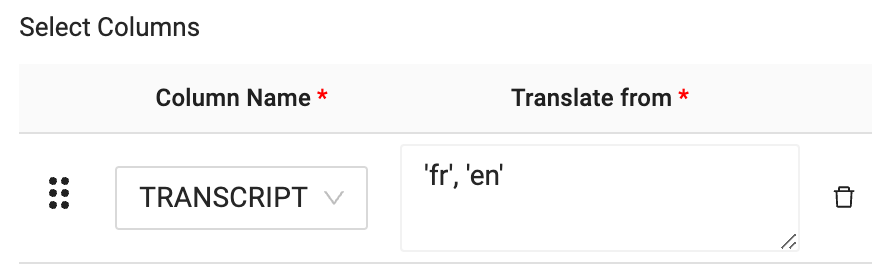
- Select Create and Run to build the object in Snowflake and populate it with data
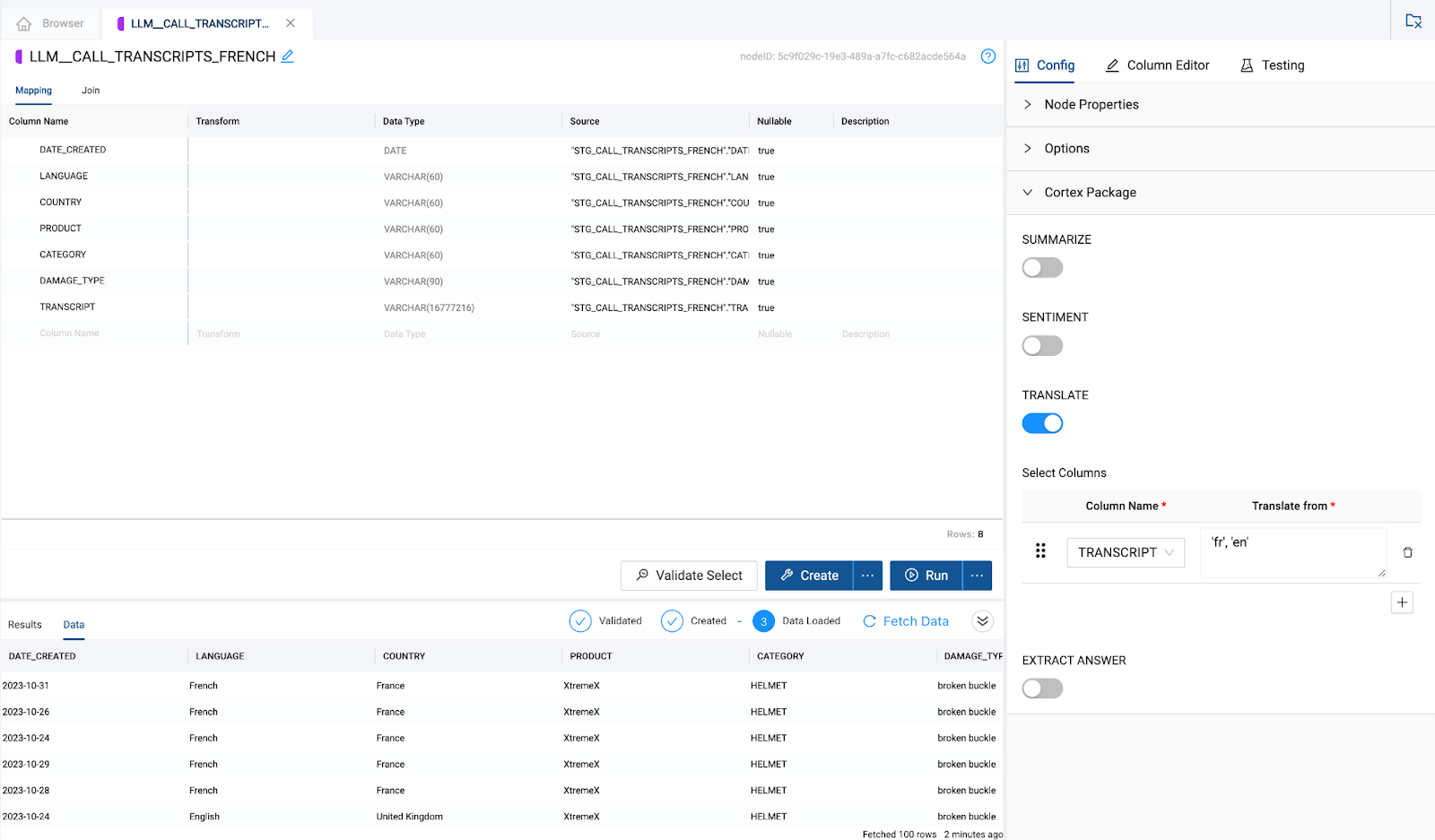
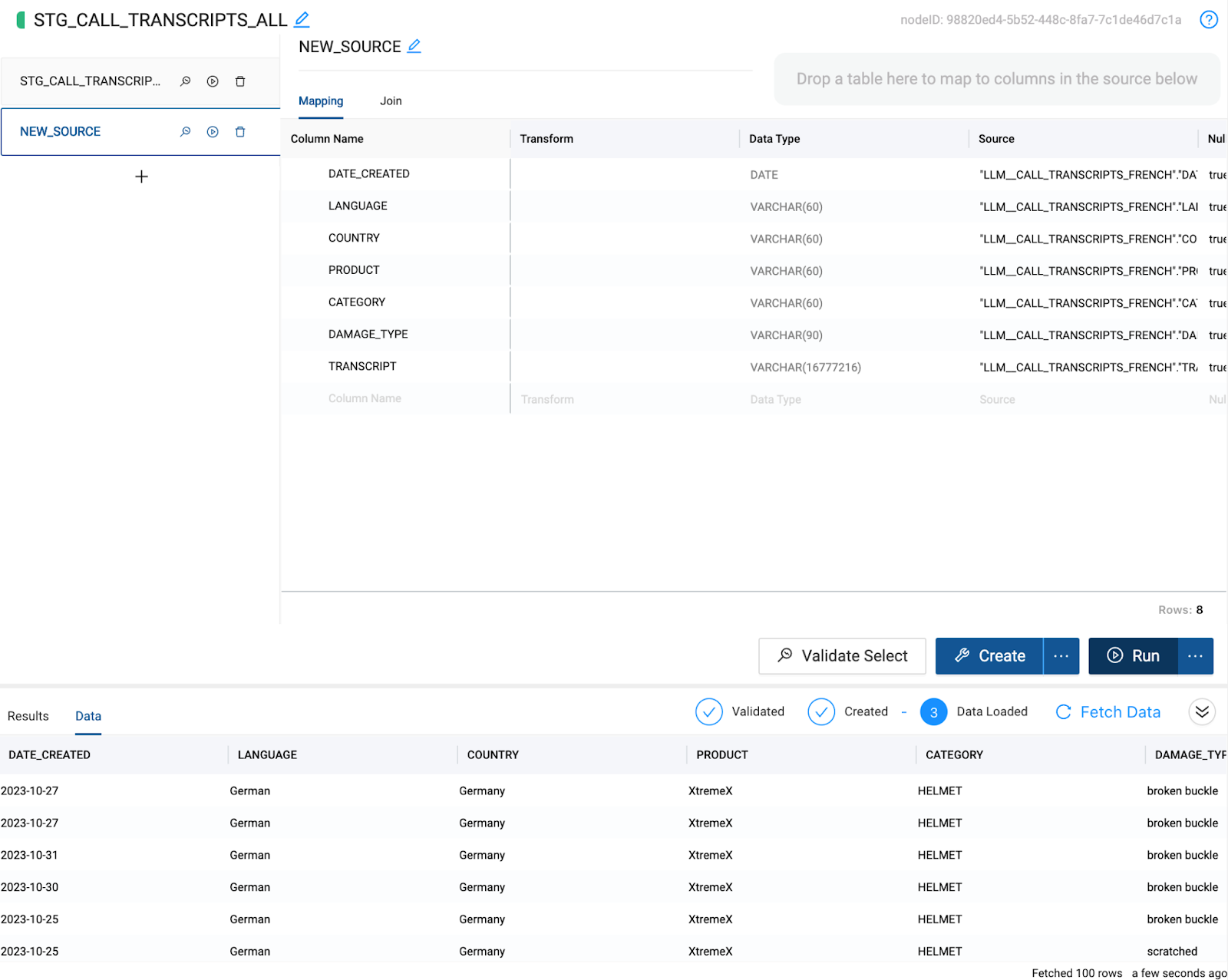
You have now processed the transcript data by translating the German and French transcripts into English. However, this translated data exists in two different tables, and in order to build an analysis on all of our transcript data, we need to unify the two tables together into one.
- Select the
LLM_CALL_TRANSCRIPTS_GERMANnode and Add Node > Stage.
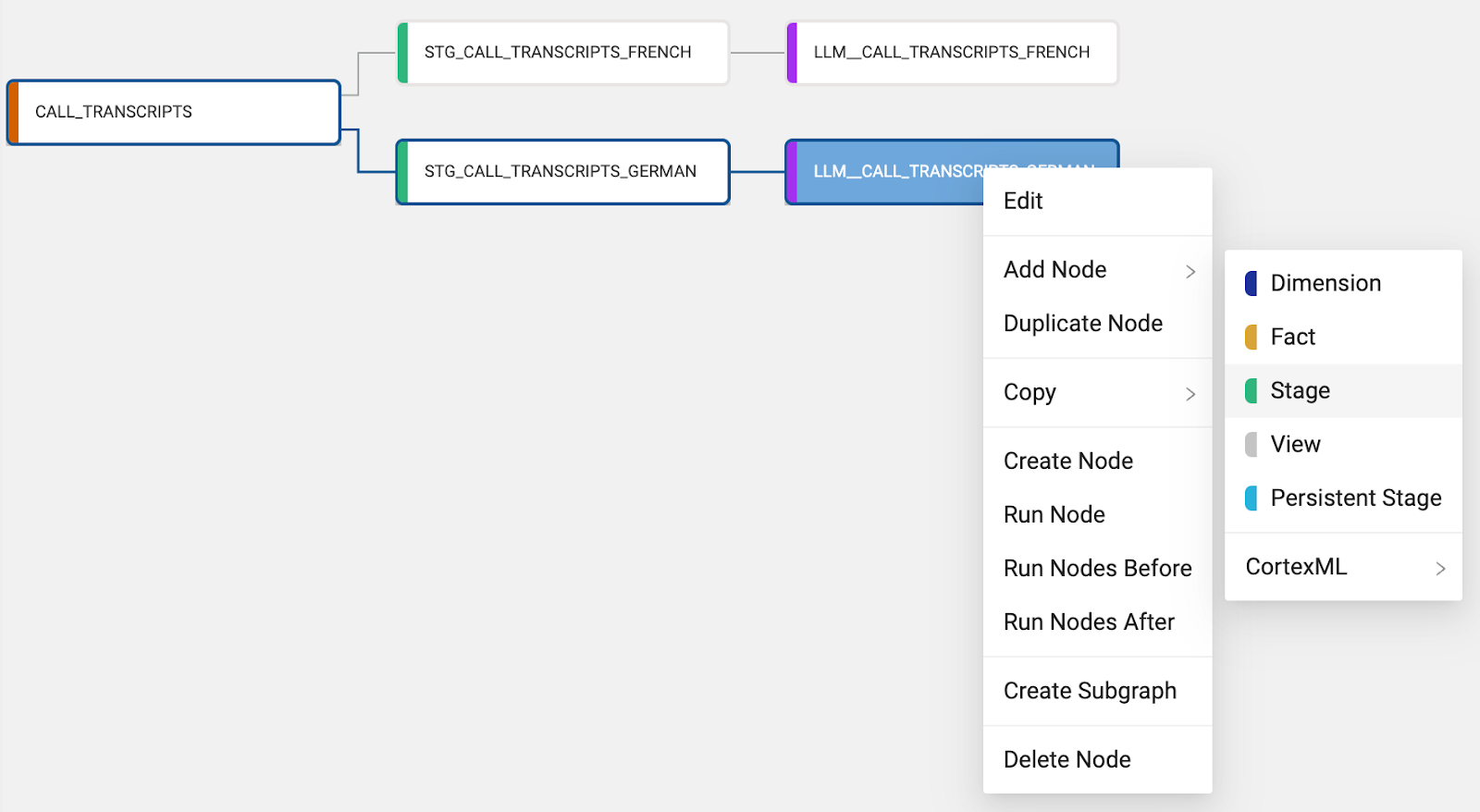
- Rename the node to
STG_CALL_TRANSCRIPTS_ALL.

- In the configuration options on the right hand side of the node, open the options dropdown and toggle on
Multi Source.
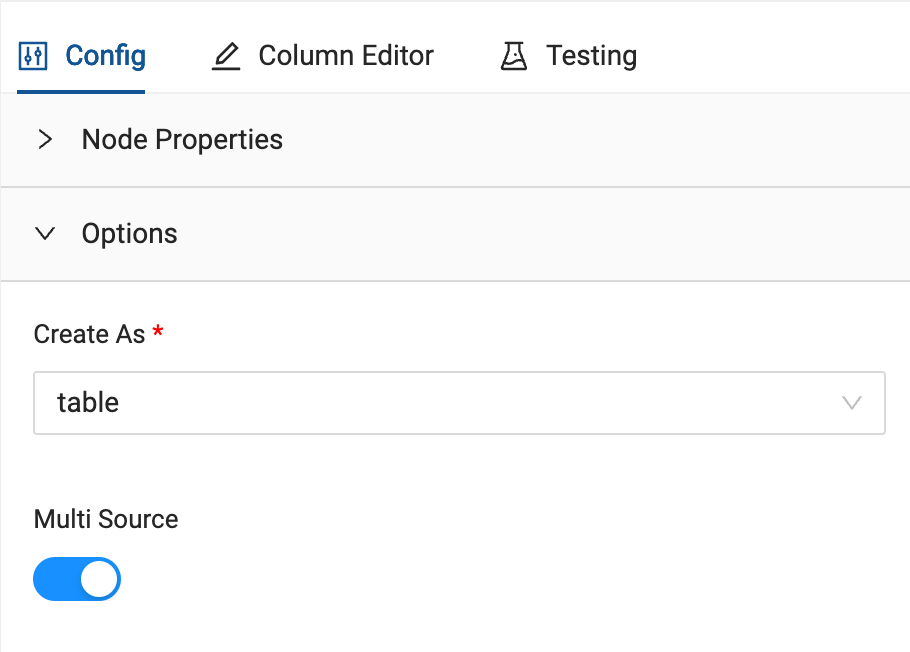
- Multi Source allows you to union together nodes with the same schema without having to write any of the code to do so. Click on the Multi Source Strategy dropdown and select
UNION ALL.

- There will be a union pane next to the columns in the mapping grid that will list all of the nodes associated with the multi source strategy of the node. Click the + button to add a node to union to the current node. You will see a new node get added to the pane called
New Source.
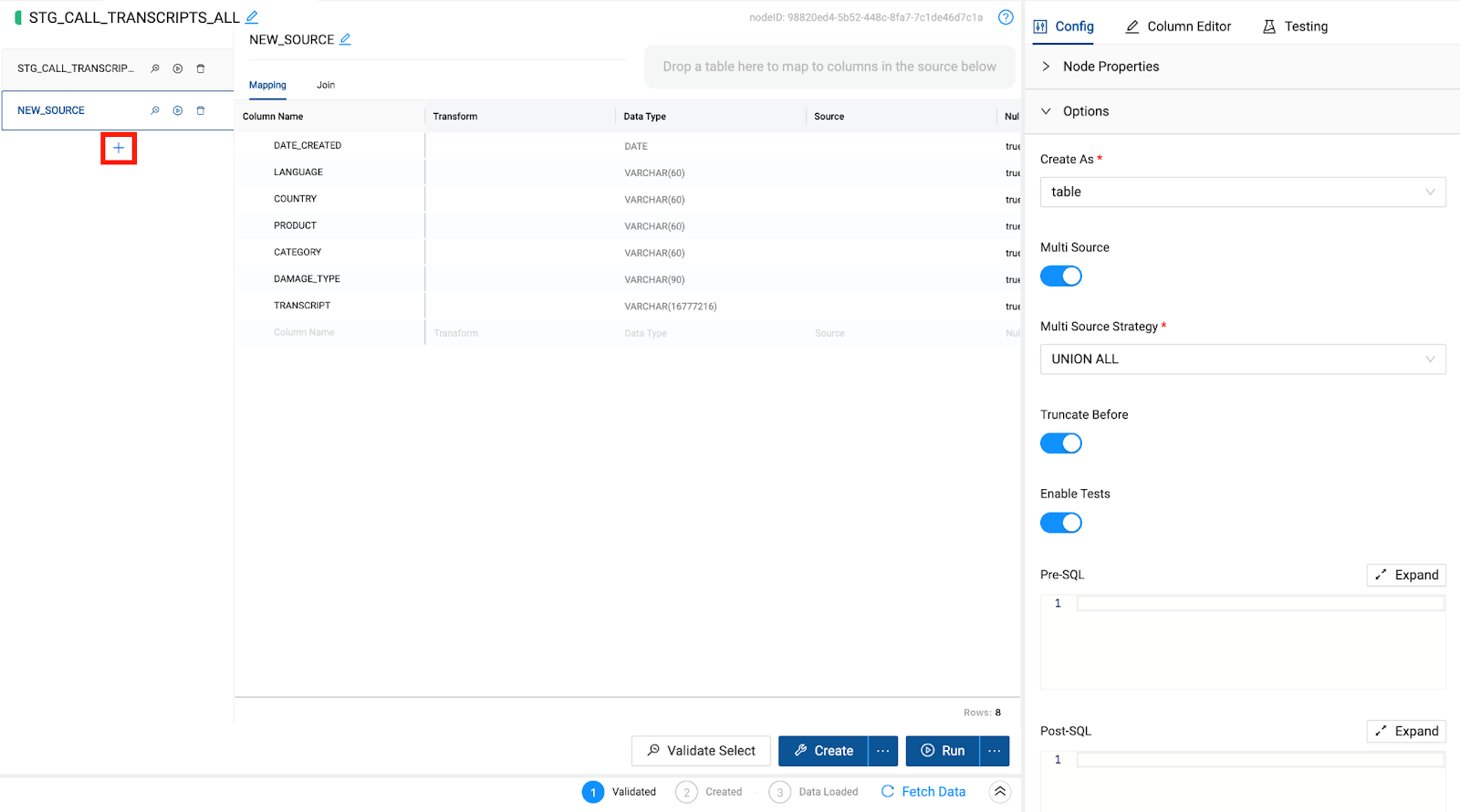
- Within this new source, there is an area to drag and drop any node from your workspace into the grid to automatically map the columns to the original node. Make sure you have the Nodes navigation menu item selected so you can view all of the nodes in your project.
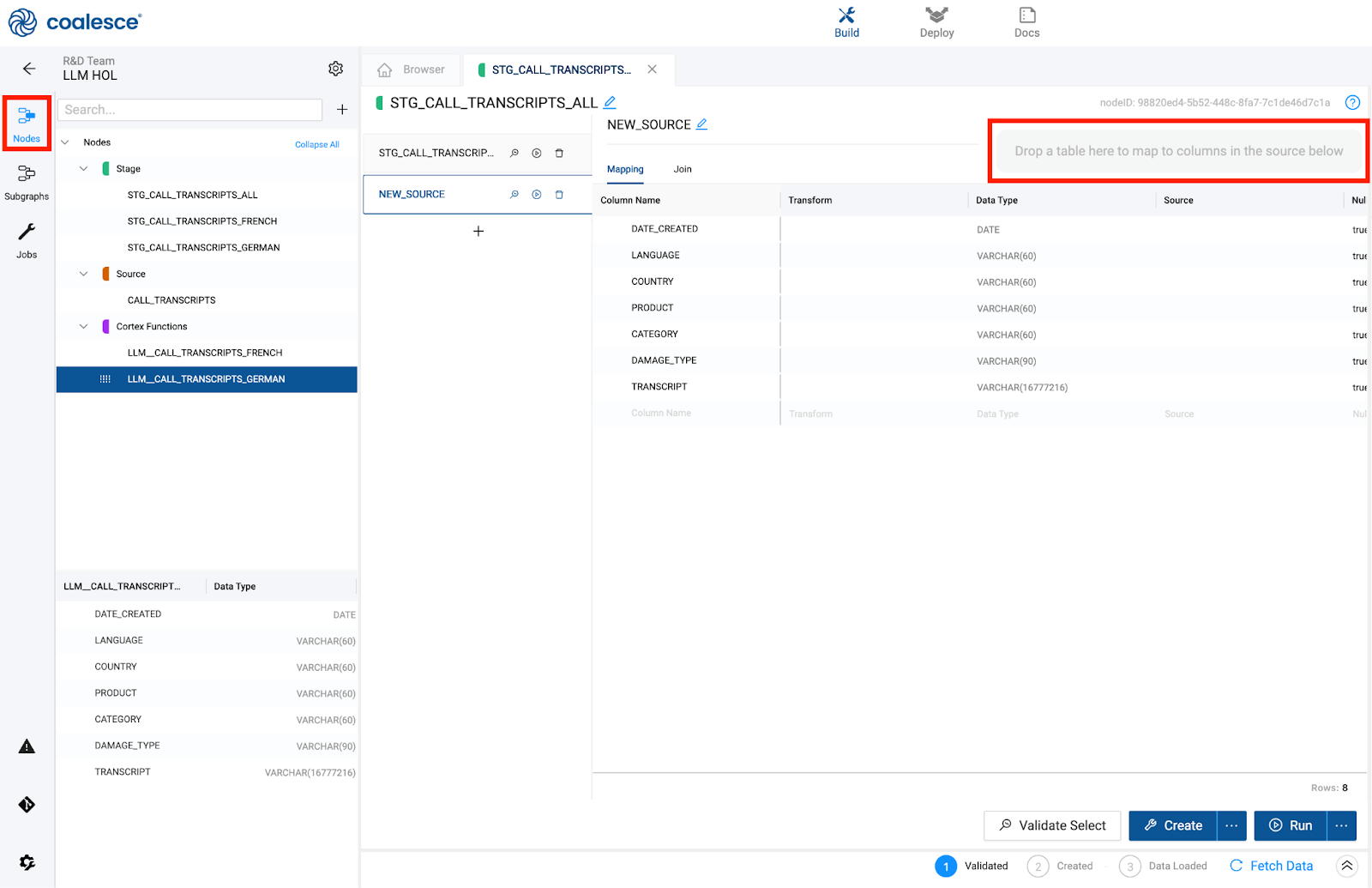
- You will now drag and drop the
LLM_CALL_TRANSCRIPTS_FRENCHnode into the multi source mapping area of the node. This will automatically map the columns to the original node i.e.LLM_CALL_TRANSCRIPTS_GERMAN.
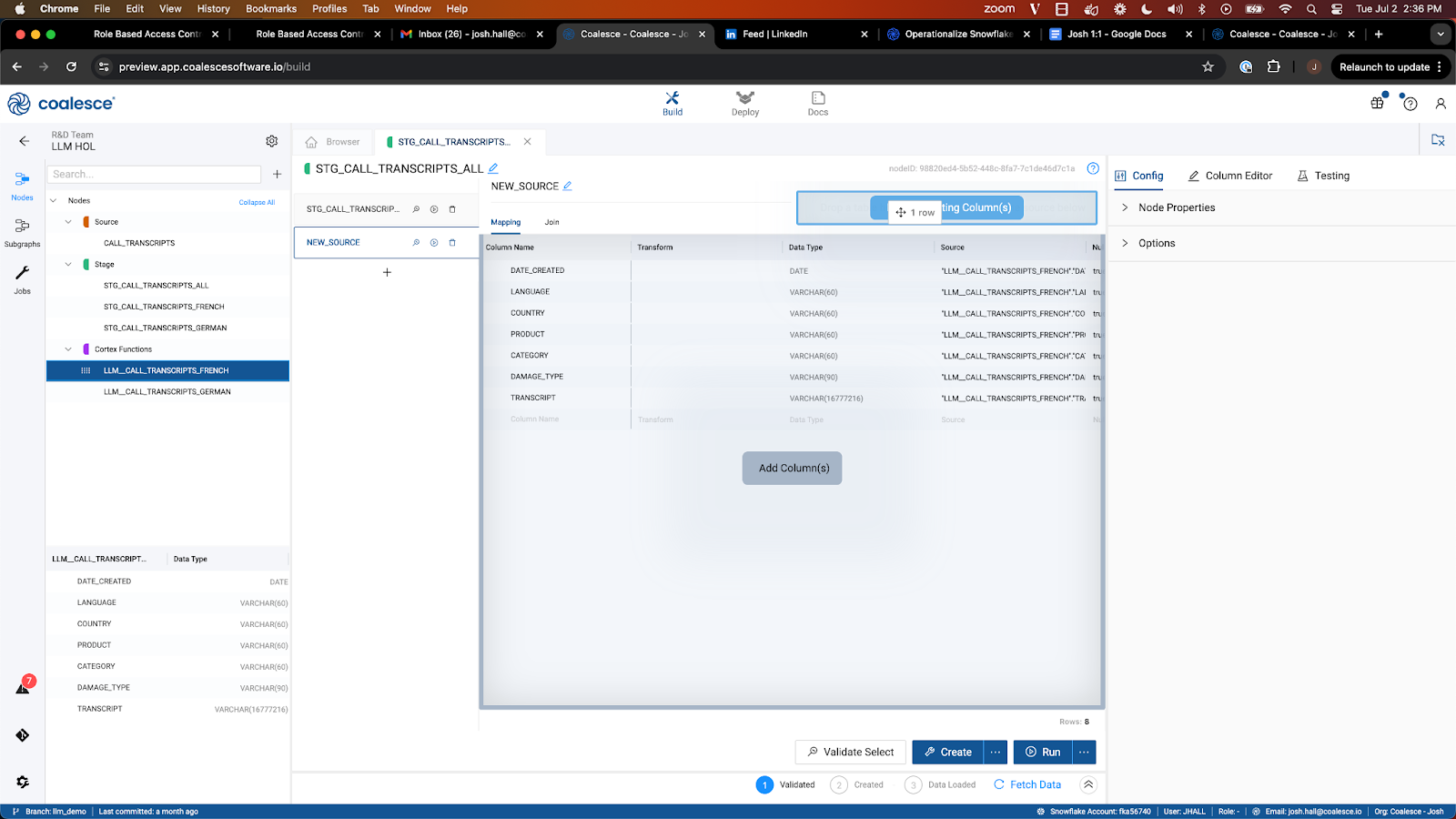
- Finally, select the join tab to configure the reference of the node we are mapping. Using metadata, Coalesce is automatically able to generate this reference for you. Hover over the Generate Join button and select Copy to Editor. Coalesce will automatically insert the code into the editor, and just like that, you have successfully unioned together the two datasets without writing a single line of code.
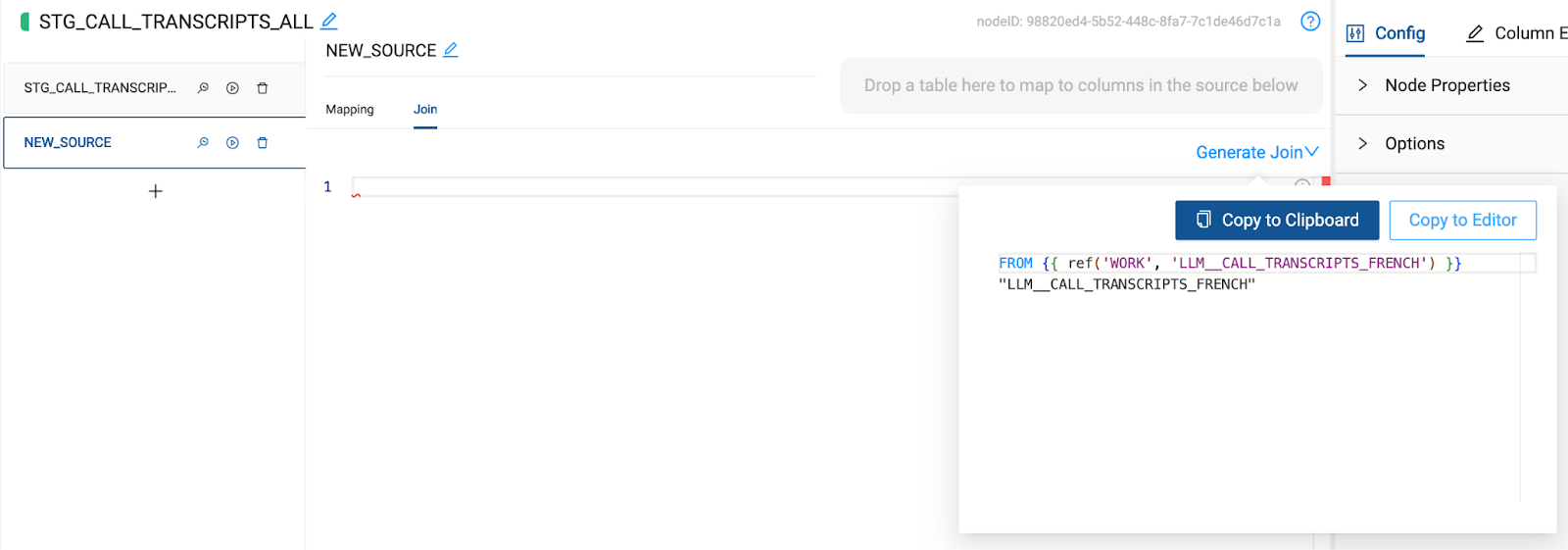
- Select Create and Run to build the object and populate it with data.
Now that we have all of our translated transcript data in the same table, we can now begin our analysis and extract insights from the data. For the sake of our use case, we want to perform a sentiment analysis on the Transcript, to understand how each of our customers felt during their interaction with our company.
Additionally, our call center reps are trained to ask for the customer's name when someone calls into the call center. Since we have this information, we want to extract the customer name from the transcript so we can associate the sentiment score with our customer to better understand their experience with our company.
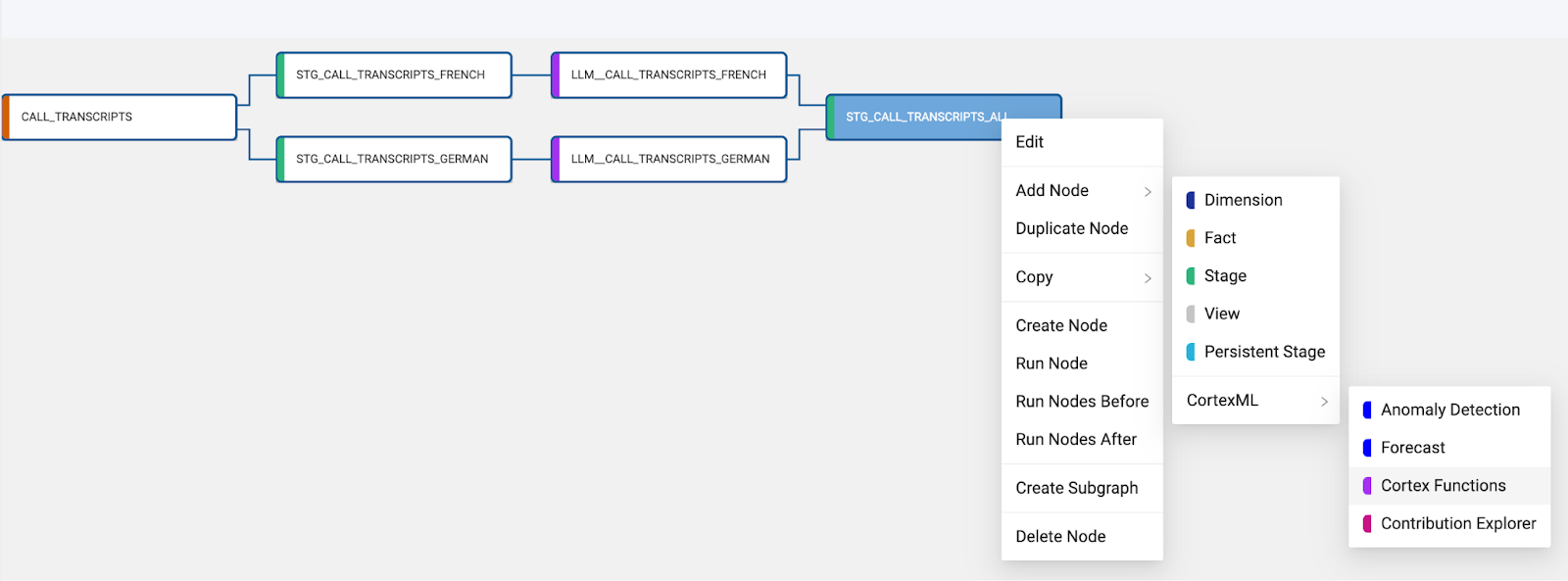
- Right click on the STG_CALL_TRANSCRIPTS_ALL node and we will add one last Cortex Function node. Add Node > CortexML > Cortex Functions.
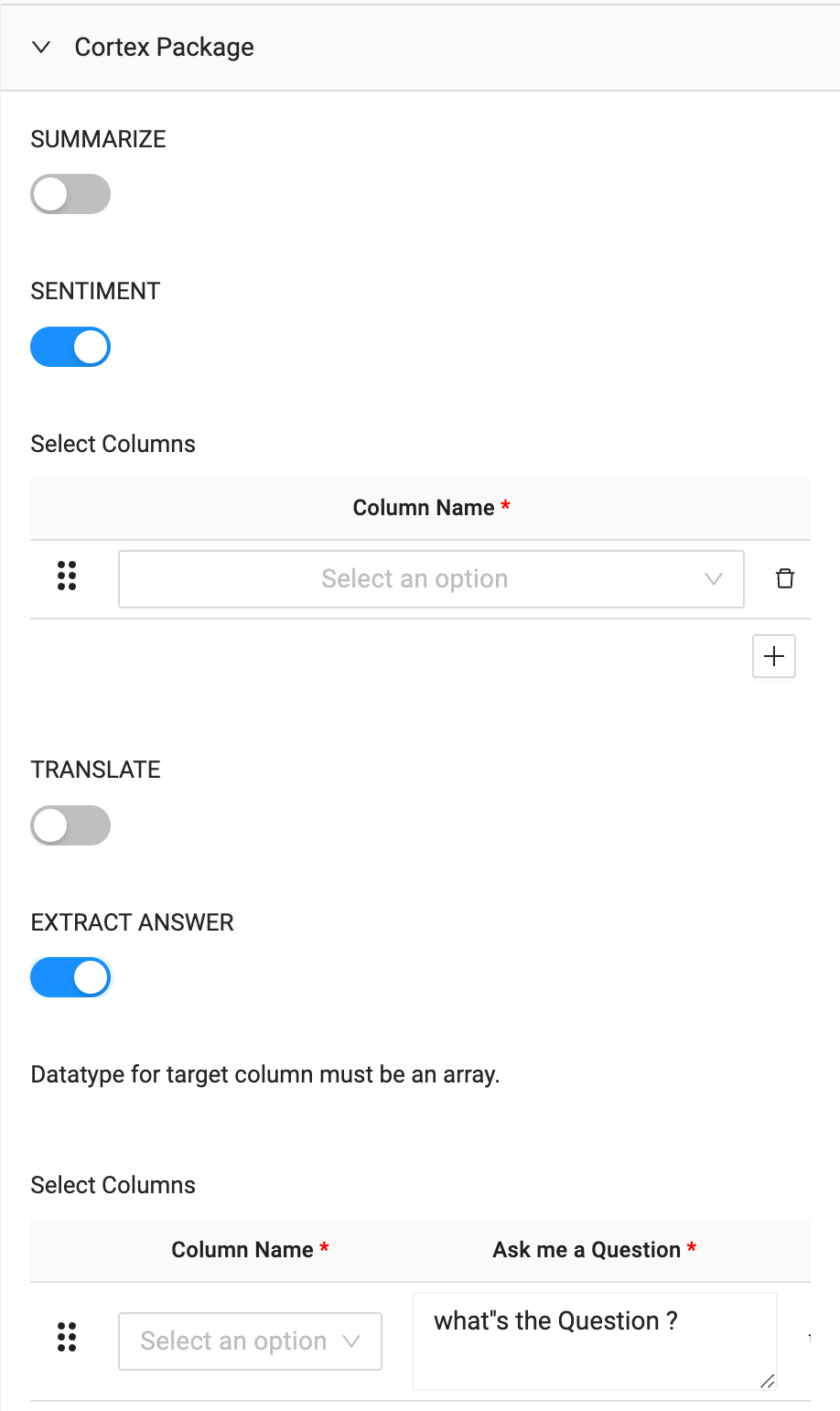
- Within the node click on the Cortex Package dropdown and toggle on
SENTIMENTandEXTRACT ANSWER.
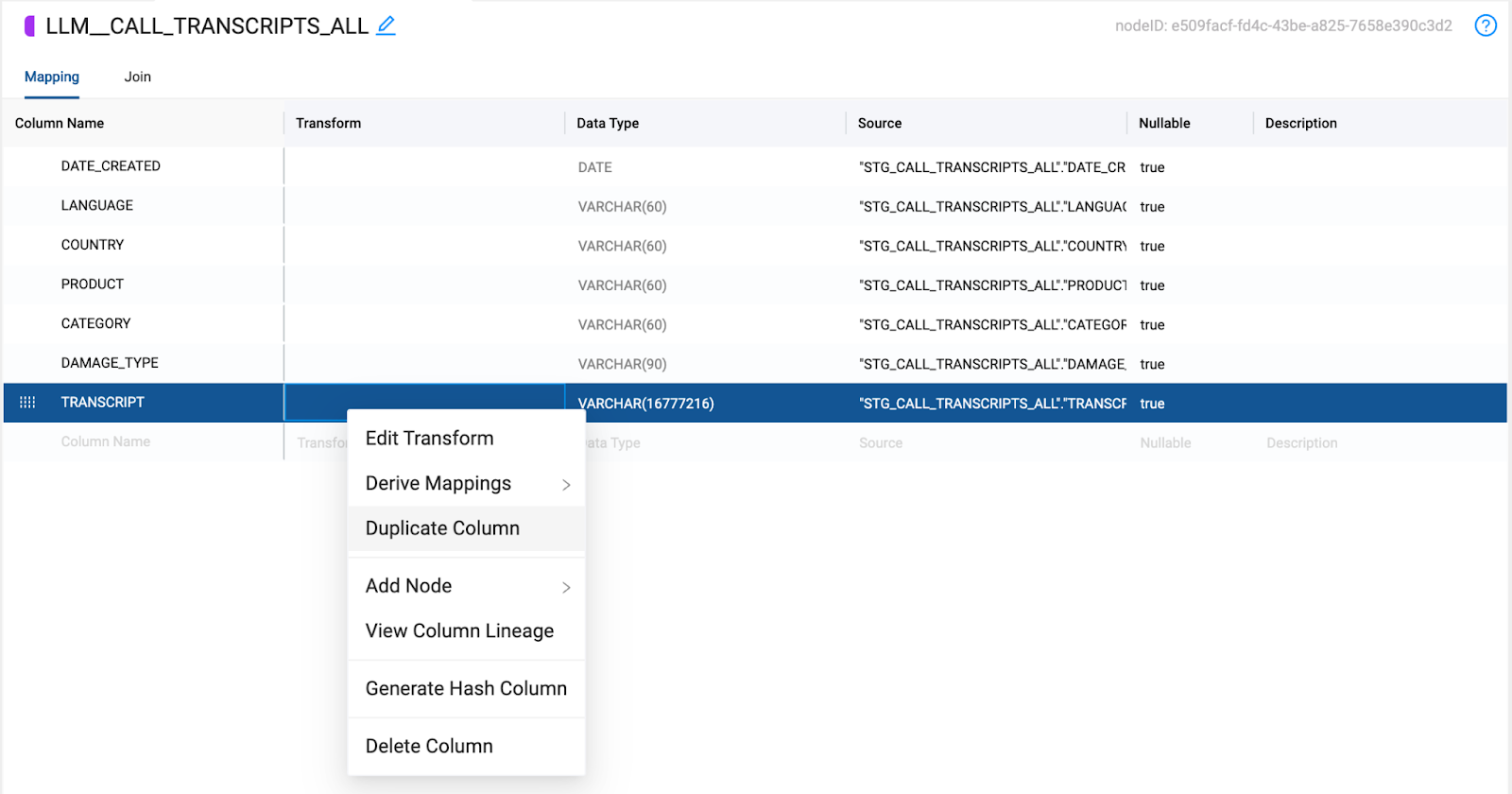
- When cortex functions are applied to a column, they overwrite the preexisting values of the column. Because of this, you will need two transcript columns to pass through to your two functions. One to perform the sentiment analysis, and one to extract the customer name from the transcript. Right click on the
TRANSCRIPTcolumn and select Duplicate Column.
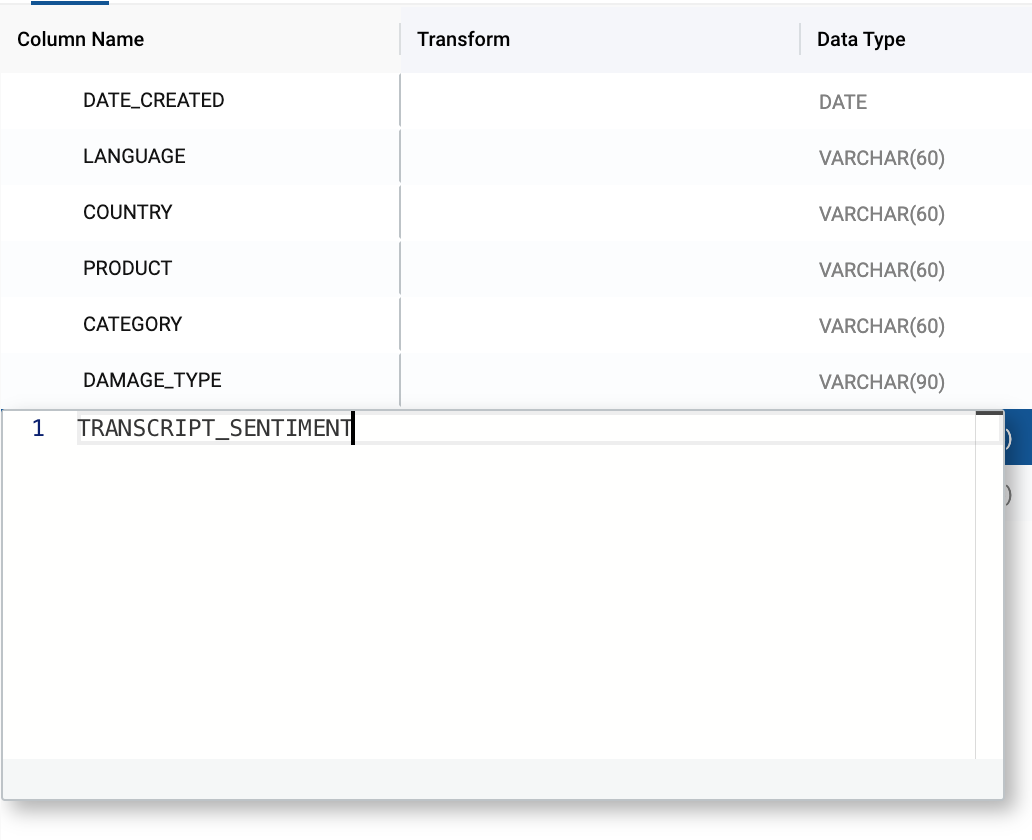
- Double click on the original
TRANSCRIPTcolumn name and rename the column toTRANSCRIPT_SENTIMENT.
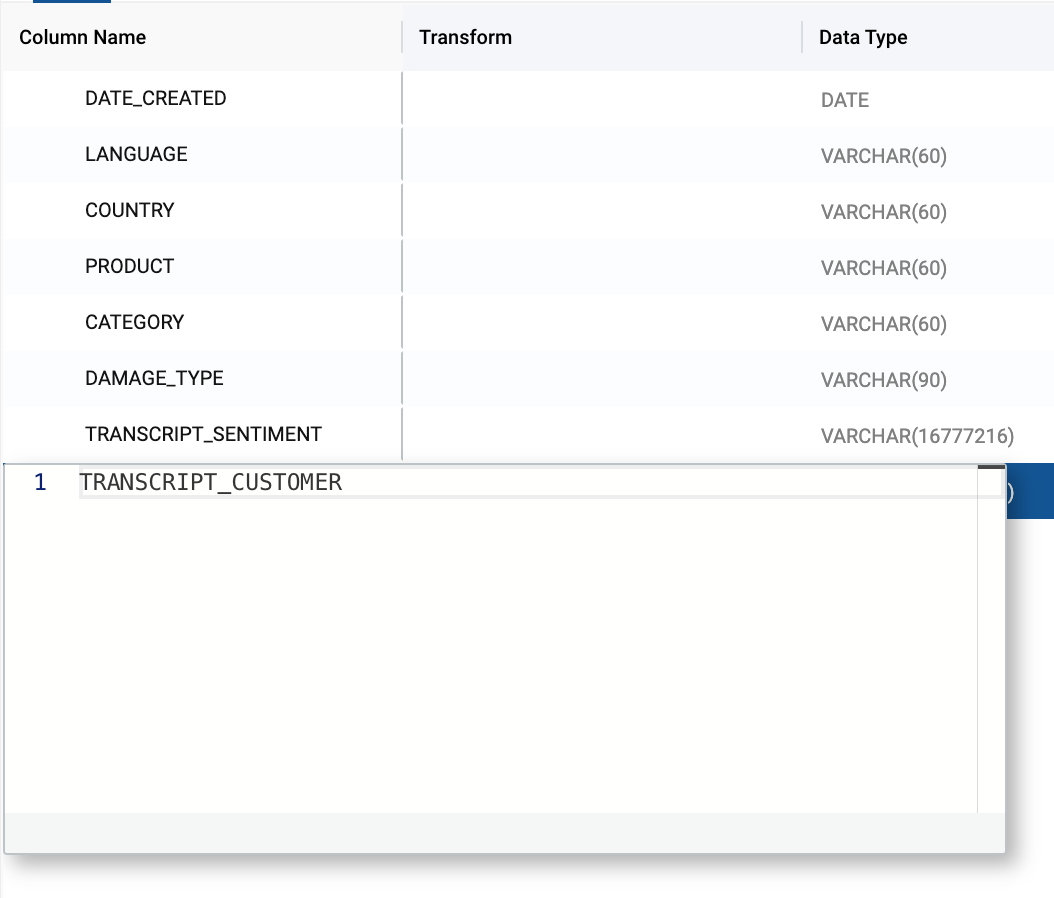
- Double click on the duplicated
TRANSCRIPTcolumn name and rename the column toTRANSCRIPT_CUSTOMER.
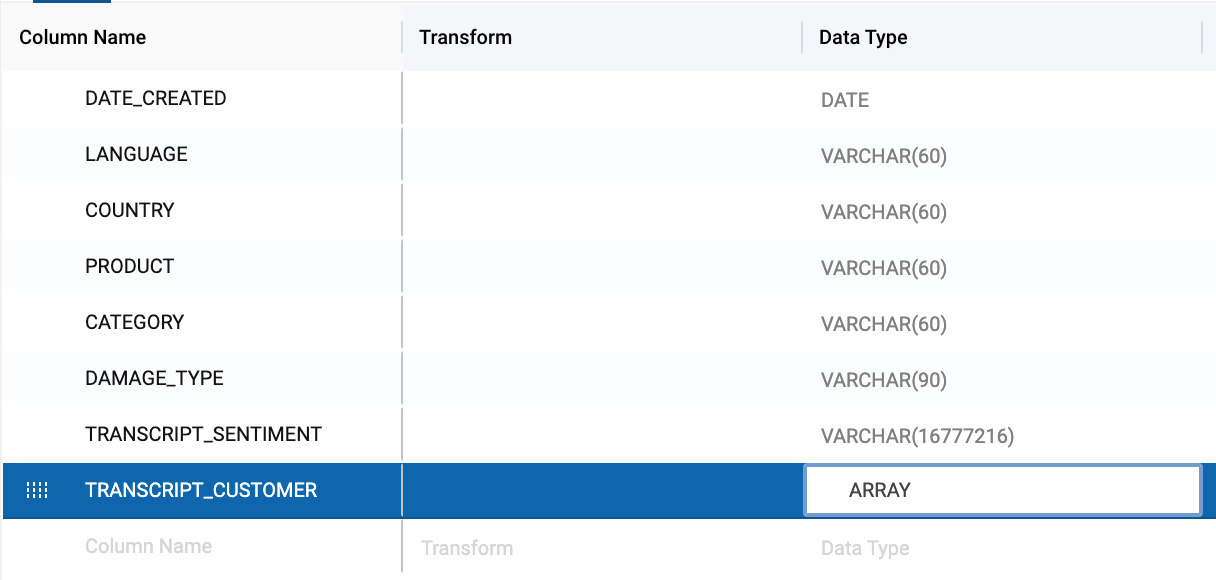
- Next, double click on the data type value for the
TRANSCRIPT_CUSTOMERcolumn. Change the data type toARRAY. This is necessary because the output of theEXTRACT ANSWERfunction is an array that contains JSON values from the extraction.
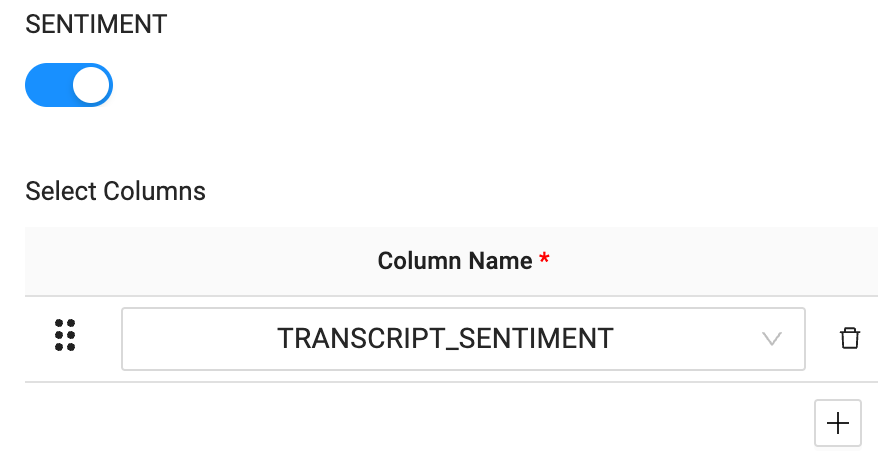
- Now that your columns are ready to be processed, we can pass them through to each function in the Cortex Package. For the
SENTIMENT ANALYSIS, select theTRANSCRIPT_SENTIMENTcolumn as the column name.
- For the
EXTRACT ANSWERfunction, select theTRANSCRIPT_CUSTOMERcolumn as the column name.
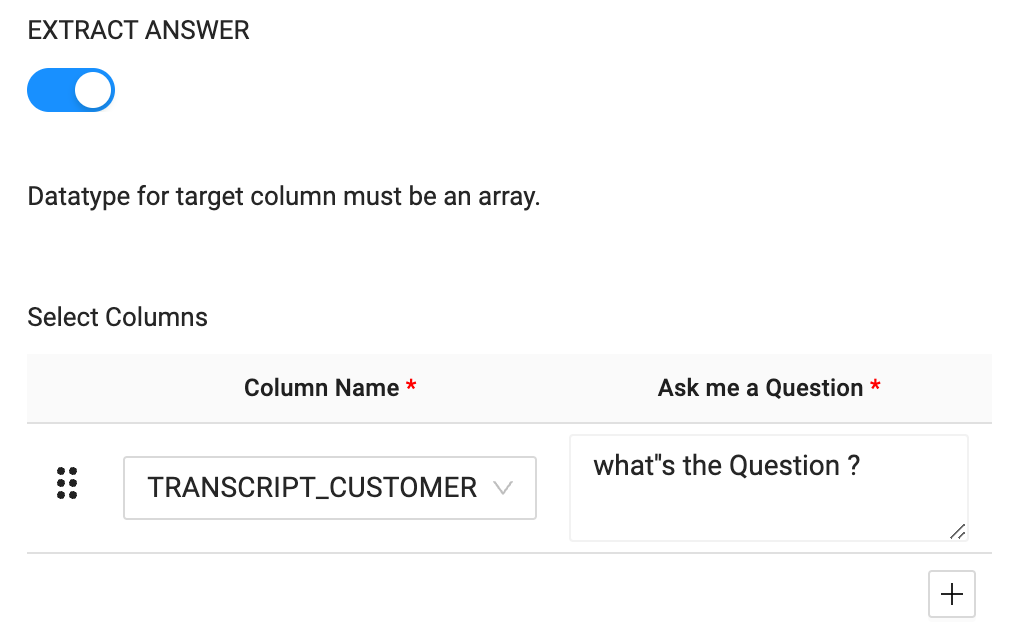
- The
EXTRACT ANSWERfunction accepts a plain text question as a parameter to use to extract the values from the text being processed. In this case, we'll ask the question "Who is the customer?"
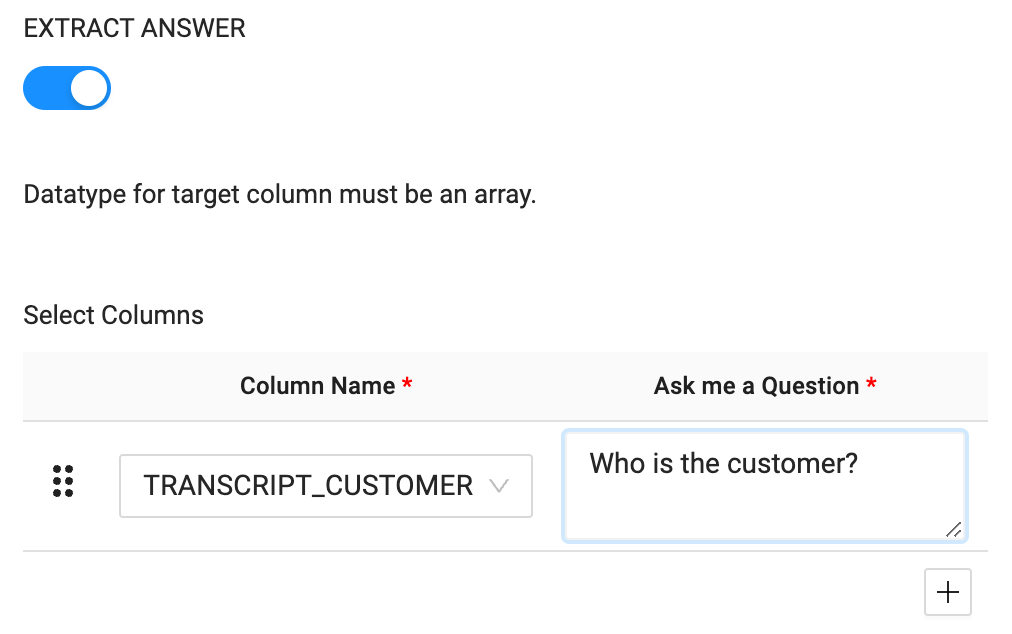
- With the node fully configured to process our sentiment analysis and answer extraction, you can Create and Run the node to build the object and populate it with the values being processed.
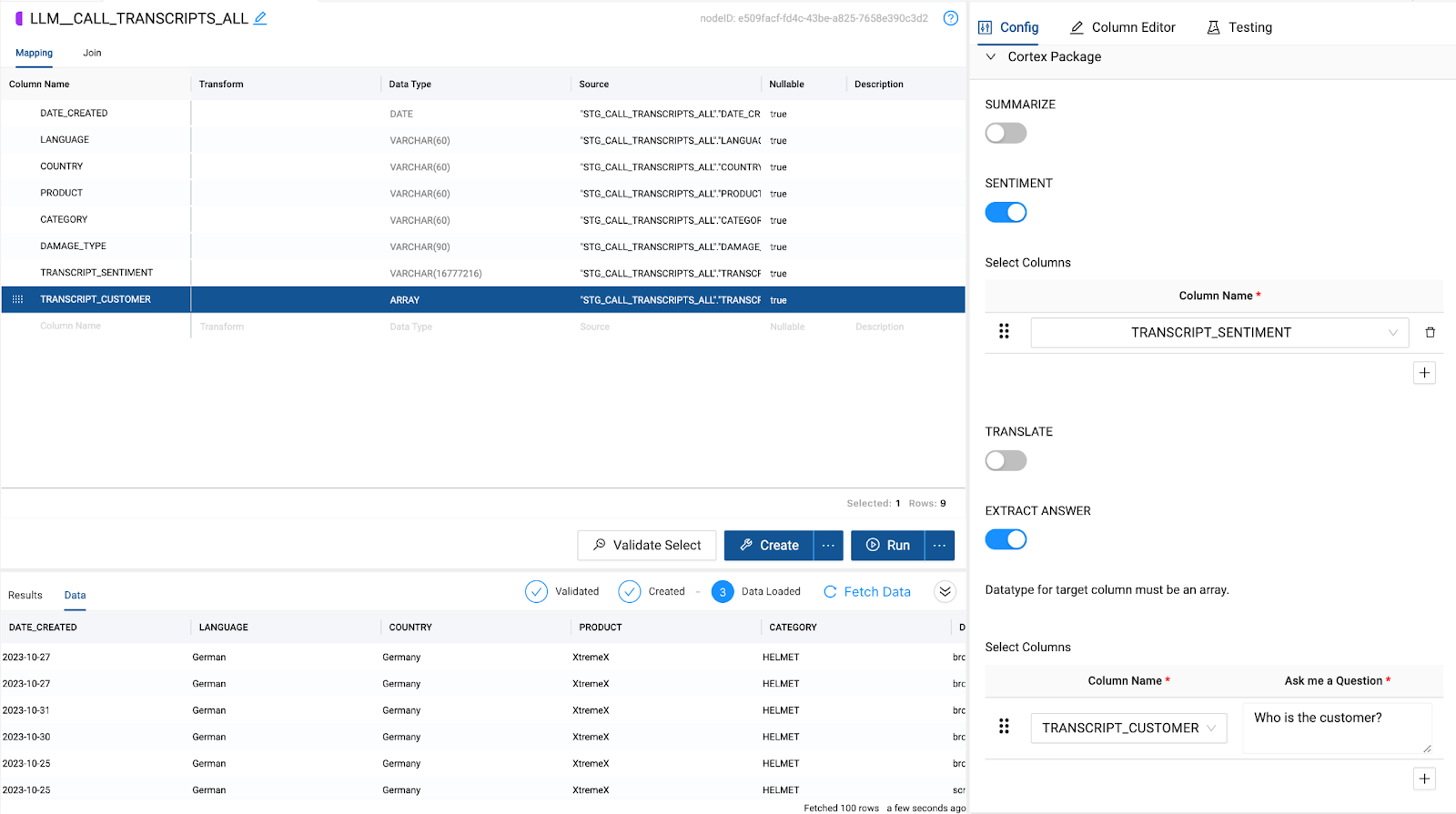
You have now used Cortex LLM Functions to process all of your text data without writing any code to configure the cortex functions, which are now ready for analysis. Let's perform some final transformations to expose for your analysis.
- Right click on the LLM_CALL_TRANSCRIPTS_ALL node and Add Node > View.
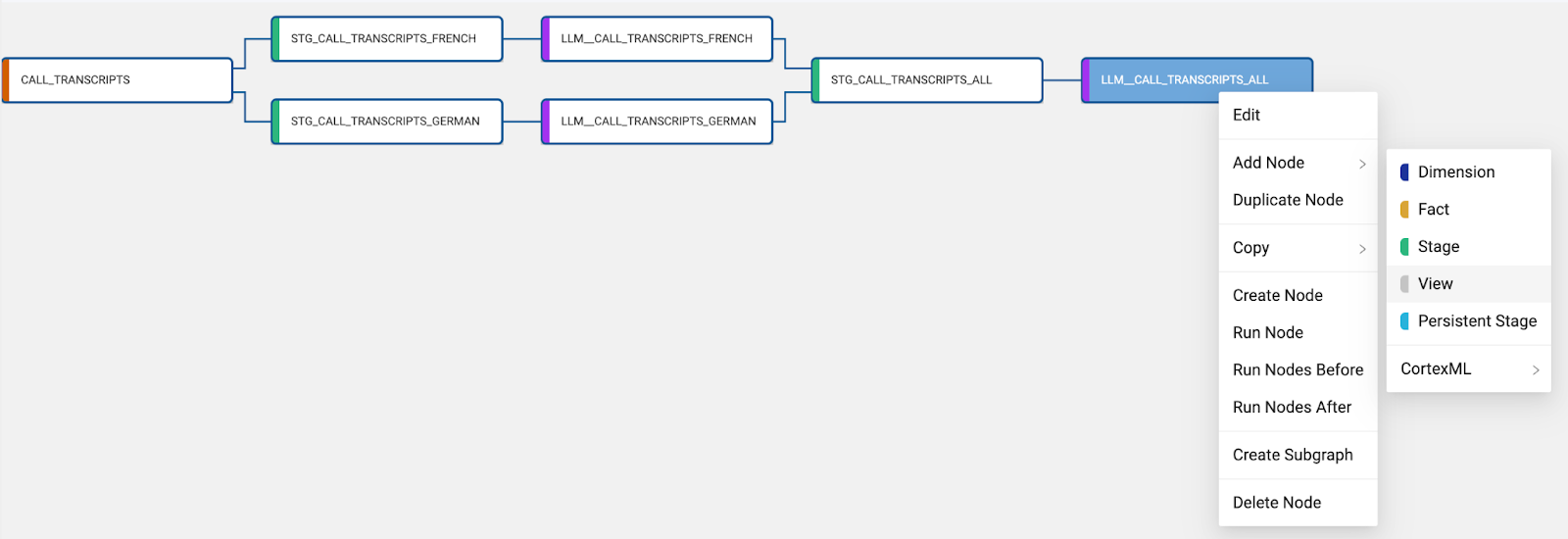
- Select the Create button and then Fetch Data. You will see the output from our LLM functions is the sentiment score and an array value containing a customer value with a confidence interval. We want to be able to extract the customer name out of the array value so we can associate the sentiment score with the customer name.
Right click on the TRANSCRIPT_CUSTOMER column and hover over Derive Mappings and select From JSON.
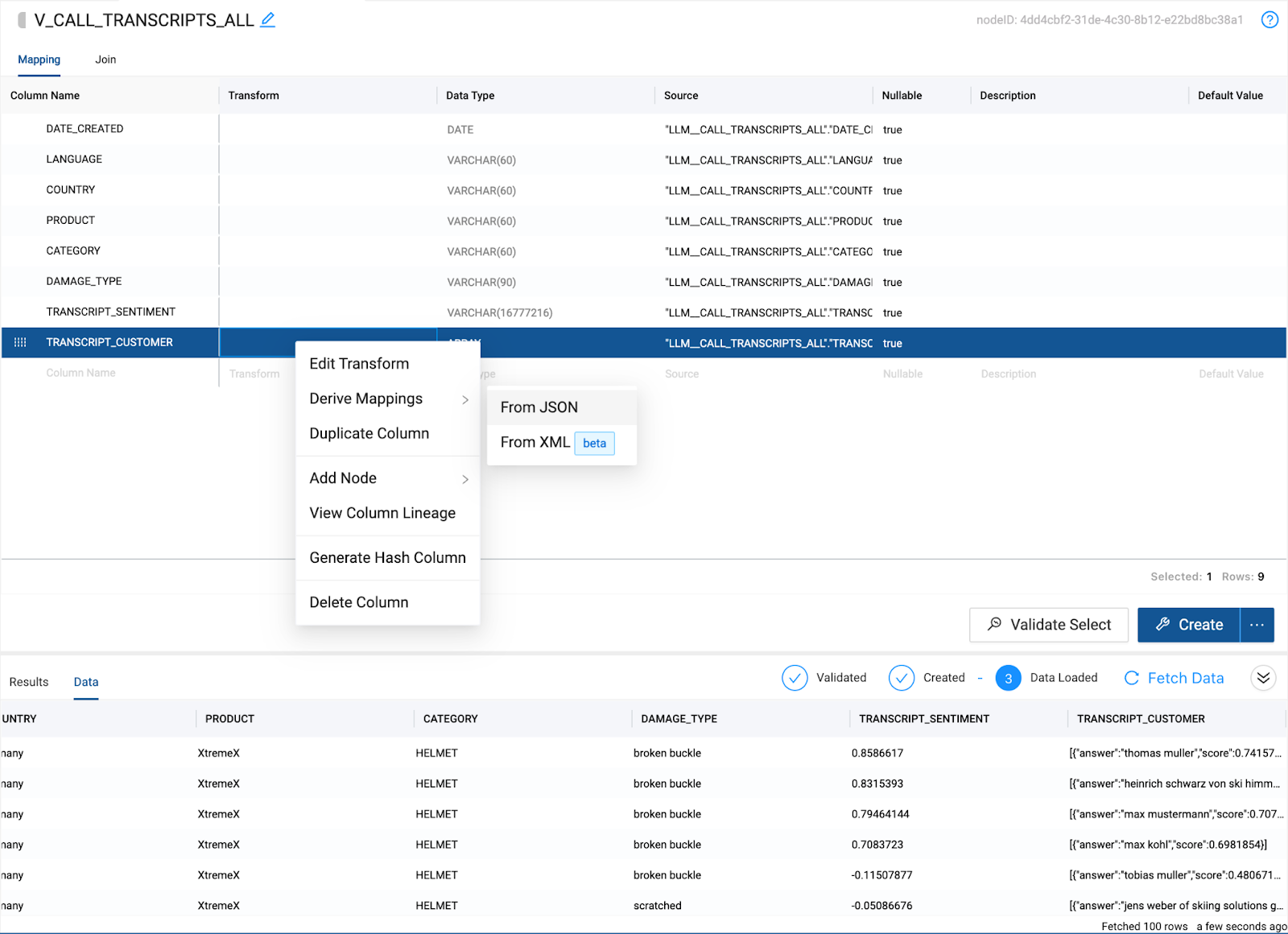
- You will see two new columns automatically created. Answer and score. The answer column contains our customer name. Double click on the answer column name and rename it to
CUSTOMER.
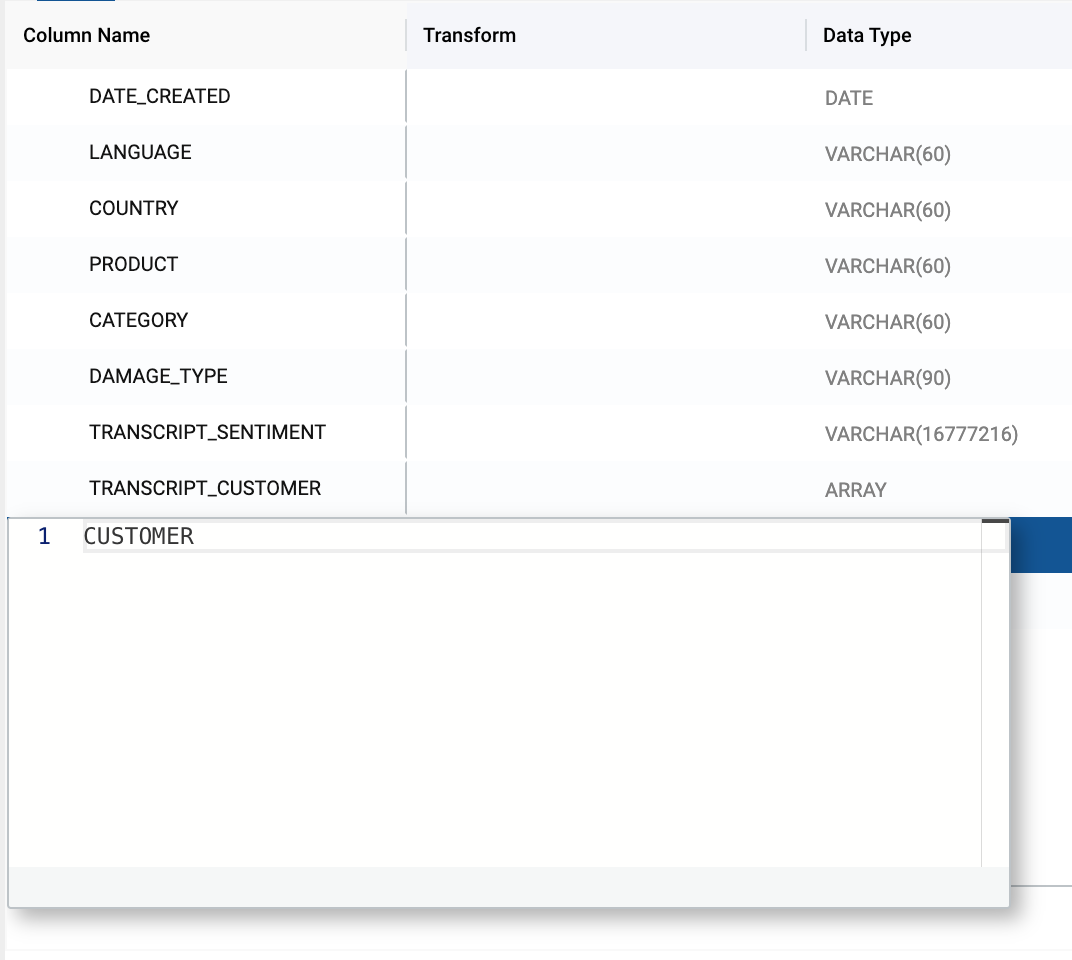
- Rename the score column to
CONFIDENCE_SCORE.
- Rerun the view by selecting Create, which will automatically rerun the query that generates the view, which will contain the updated CUSTOMER column we just created.
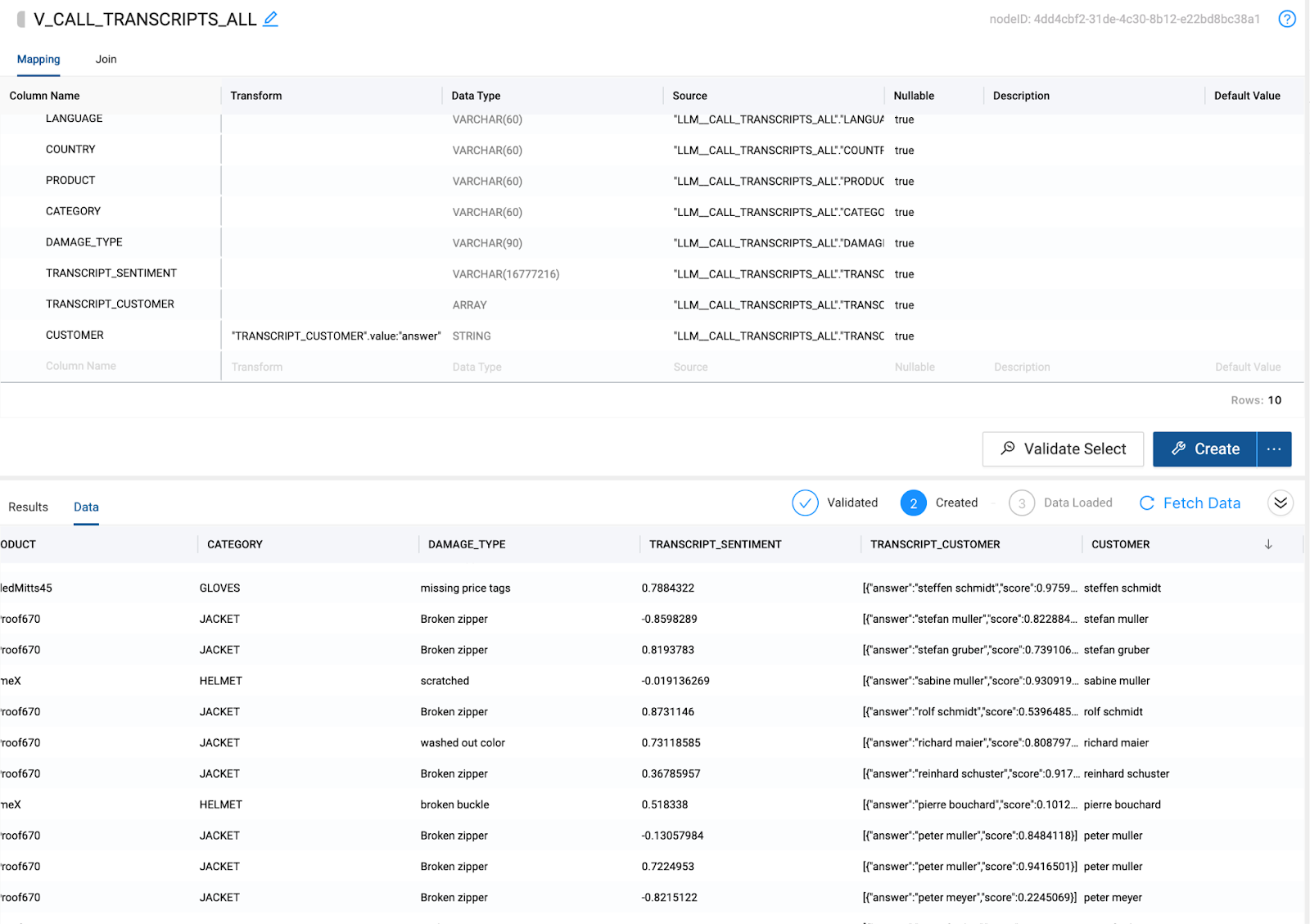
Now that you have created a view in Snowflake that contains all of the data you needed for your analysis, you can query the view we just created to learn more about the data.
- Open a worksheet in Snowflake and paste in the following query which analyzes the sentiment of each customer.
select customer, transcript_sentiment
from pc_coalesce_db.public.v_call_transcripts_all
where confidence_score > .8
This query is allowing us to view all of the customers and their associated sentiment, where the likelihood of the customer name being correct is 80% or higher.
- You can use Snowsight to graphically represent this data. Select Chart from the results pane and select a Bar chart if not already selected.
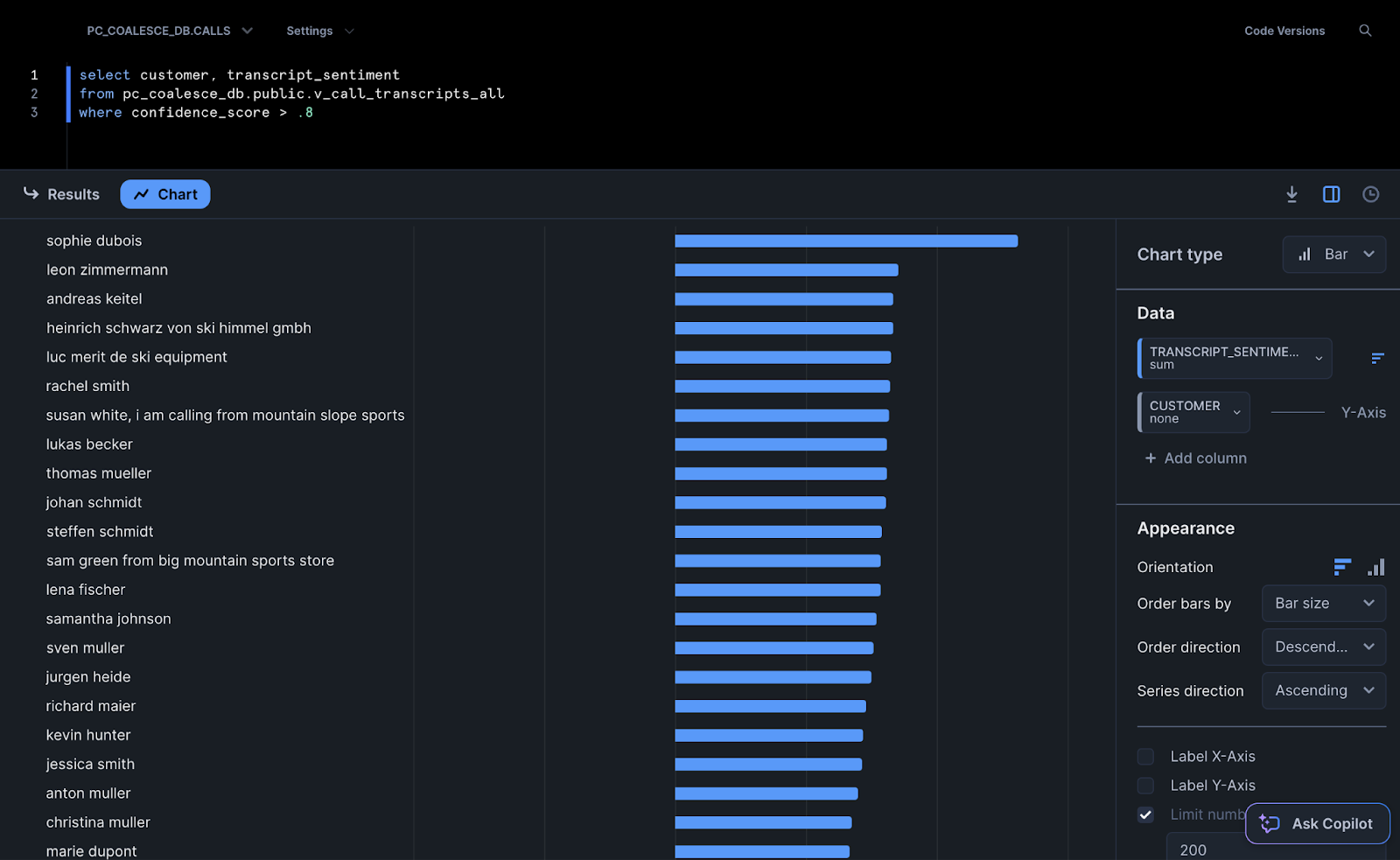
Additionally, you can uncheck the box next to Limit number of bars to see all of your results.
- Another question you may need to answer for the business, is what damage types have the lowest sentiment. You can copy and paste the query here to evaluate the answer to this question.
select damage_type, avg(transcript_sentiment)
from pc_coalesce_db.public.v_call_transcripts_all
where transcript_sentiment < 0
group by damage_type
This query allows you to see the aggregated average sentiment towards damage types, where the sentiment is below zero. This would allow decision makers to understand which damages are the most frustrating for customers, and take action on how to improve processes to avoid these damages.
- Again, you can use Snowsight to graphically analyze the data using a chart with bars.
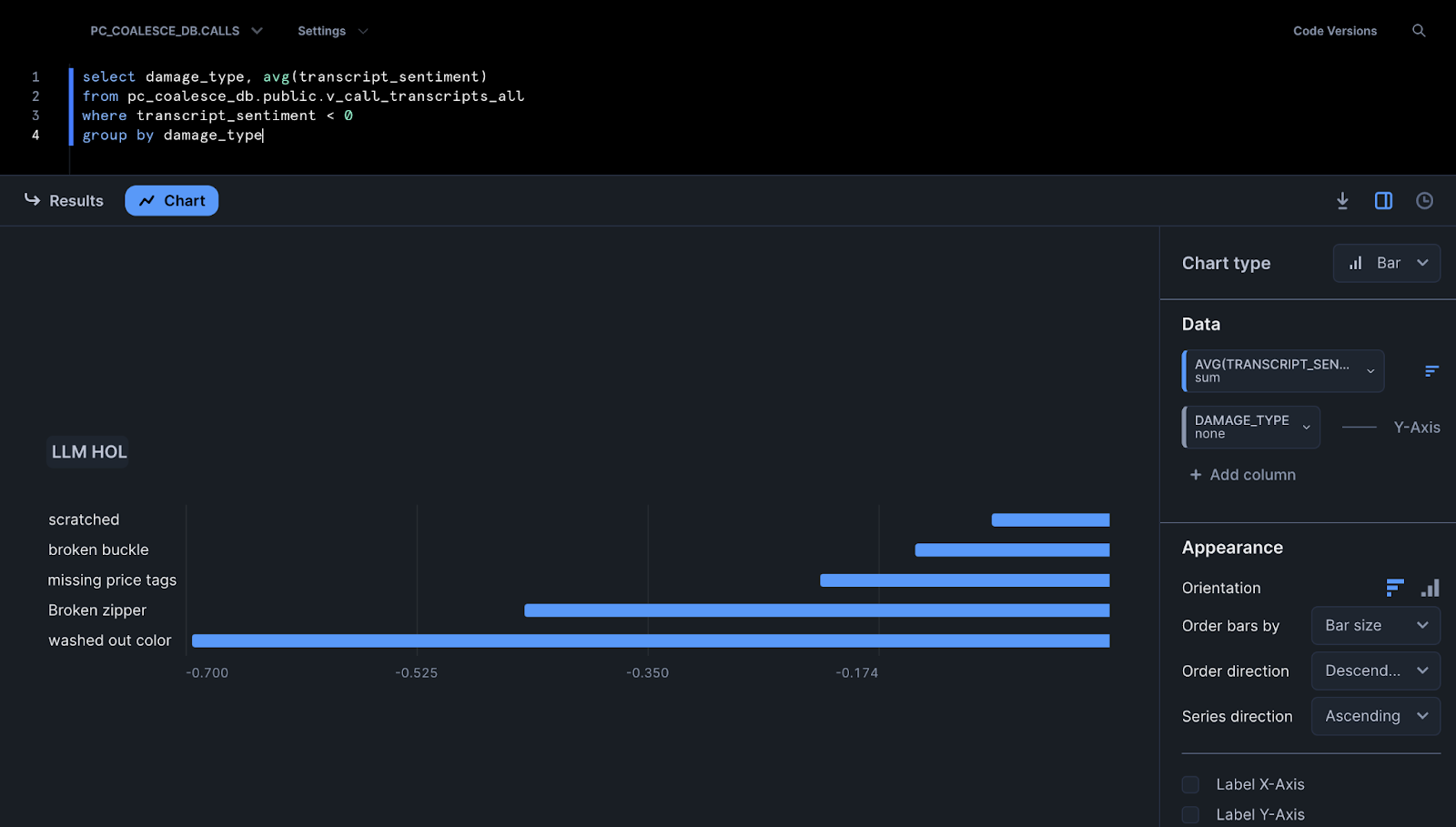
- With this view now in Snowflake, you can continue to analyze this data and obtain more insights and inferences about everything surrounding the call transcripts that traditionally would be incredibly difficult to gain the same value from without the ease of using Cortex LLM functions in Coalesce.
Congratulations on completing your lab! You've mastered the basics of building and managing Snowflake Cortex LLM functions in Coalesce and can now continue to build on what you learned. Be sure to reference this exercise if you ever need a refresher.
We encourage you to continue working with Coalesce by using it with your own data and use cases and by using some of the more advanced capabilities not covered in this lab.
What we've covered
- How to navigate the Coalesce interface
- Configure storage locations and mappings
- How to add data sources to your graph
- How to prepare your data for transformations with Stage nodes
- How to union tables
- How to set up and configure Cortex LLM Nodes
- How to analyze the output of your results in Snowflake
Continue with your free trial by loading your own sample or production data and exploring more of Coalesce's capabilities with our documentation and resources. For more technical guides on advanced Coalesce and Snowflake features, check out Snowflake Quickstart guides covering Dynamic Tables and Cortex ML functions.
Additional Coalesce Resources
Reach out to our sales team at coalesce.io or by emailing sales@coalesce.io to learn more!